23 KiB
MySQL多表查询与事务
学习目标
- 能够理解三大范式
- 能够使用内连接进行多表查询
- 能够使用左外连接和右外连接进行多表查询
- 能够使用子查询进行多表查询
- 能够理解多表查询的规律
- 能够理解事务的概念
- 能够说出事务的原理
- 能够在MySQL中使用事务
- 能够理解脏读,不可重复读,幻读的概念及解决办法
第一章 数据库的三大范式
目标
能够说数据库中有哪三大范式?每个范式的含义是什么?
讲解
什么是范式
范式是指:设计数据库表的规则(Normal Form) 好的数据库设计对数据的存储性能和后期的程序开发,都会产生重要的影响。建立科学的,规范的数据库就需要满足一些规则来优化数据的设计和存储
范式的基本分类
目前关系数据库有五种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。一般说来,数据库只需满足第三范式(3NF)就行了。
第一范式
即数据库表的每一列都是不可分割的原子数据项,而不能是集合、数组、记录等非原子数据项。即实体中的某个属性有多个值时,必须拆分为不同的属性。在符合第一范式(1NF)表中每个列的值只能是表的一个属性或一个属性的一部分。简而言之,第一范式每一列不可再拆分,称为原子性。
第一范式:表中每一列不能再拆分

总结:如果不遵守第一范式,查询出数据还需要进一步处理(查询不方便)。遵守第一范式,需要什么字段的数据就查询什么数据(方便查询)。
第二范式
第二范式(2NF)要求数据库表中的每个实例或记录必须可以被唯一地区分。选取一个能区分每个实体的属性或属性组,作为实体的唯一标识。例如在员工表中的身份证号码即可实现每个员工的区分,该身份证号码即为候选键,任何一个候选键都可以被选作主键。在找不到候选键时,可额外增加属性以实现区分。 第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性。如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。简而言之,第二范式就是在第一范式的基础上属性完全依赖于主键。
第二范式:
- 一张表只描述一件事情
- 表中的每一个字段都依赖于主键
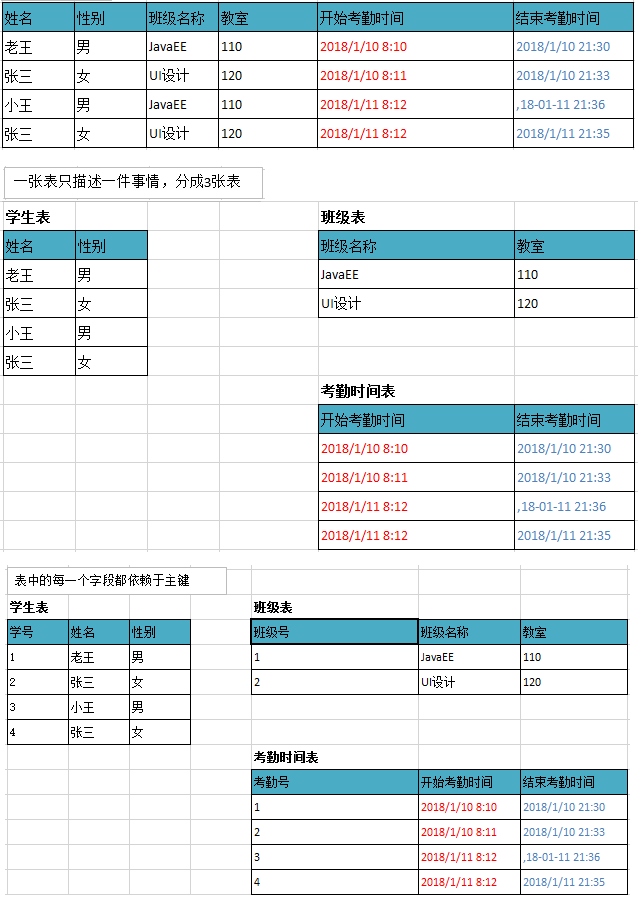

总结:如果不准守第二范式,数据冗余,相同数据无法区分。遵守第二范式减少数据冗余,通过主键区分相同数据。
第三范式
在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖) 第三范式(3NF)是第二范式(2NF)的一个子集,即满足第三范式(3NF)必须满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个关系中不包含已在其它关系已包含的非主关键字信息。
第三范式:从表的外键必须使用主表的主键

总结:如果不准守第三范式,可能会有相同数据无法区分,修改数据的时候多张表都需要修改(不方便修改)。遵守第三范式通过id可以区分相同数据,修改数据的时候只需要修改一张表(方便修改)。
小结
第一范式要求? 表中的字段不能再拆分(字段原子性)
第二范式要求? 1.一张表描述一件事情 2.每个表都提供主键
第三范式要求? 从表的外键必须使用主表的主键
第二章 多表查询介绍
目标
了解什么是多表查询,及多表查询的两种方式
讲解
什么是多表查询
同时查询多张表获取到需要的数据
比如:我们想查询到开发部有多少人,需要将部门表和员工表同时进行查询

多表查询的分类

小结
什么是多表查询?通过查询多张表获取我们想要的数据
笛卡尔积现象
目标
能够说出什么是笛卡尔积,以及如何消除笛卡尔积
讲解
准备数据
CREATE DATABASE day15;
USE day15;
-- 创建部门表
CREATE TABLE dept (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20)
);
INSERT INTO dept (NAME) VALUES ('开发部'),('市场部'),('财务部');
-- 创建员工表
CREATE TABLE emp (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(10),
gender CHAR(1), -- 性别
salary DOUBLE, -- 工资
join_date DATE, -- 入职日期
dept_id INT
);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('孙悟空','男',7200,'2013-02-24',1);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('猪八戒','男',3600,'2010-12-02',2);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('唐僧','男',9000,'2008-08-08',2);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('白骨精','女',5000,'2015-10-07',3);
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('蜘蛛精','女',4500,'2011-03-14',1);
什么是笛卡尔积现象
需求:查询每个部门有哪些人
具体操作:
SELECT * FROM dept, emp;

以上数据其实是左表的每条数据和右表的每条数据组合。左表有3条,右表有5条,最终组合后3*5=15条数据。
左表的每条数据和右表的每条数据组合,这种效果称为笛卡尔乘积

如何清除笛卡尔积现象的影响
我们发现不是所有的数据组合都是有用的,只有员工表.dept_id = 部门表.id 的数据才是有用的。所以需要通过条件过滤掉没用的数据。

SELECT * FROM dept, emp WHERE emp.`dept_id`=dept.`id`;

小结
- 能够说出什么是笛卡尔积? 左表的每条记录和右表的每条记录会组合起来
- 如何消除笛卡尔积 只查询满足要求的数据,通常都是外键等于主键
内连接
目标
能够掌握内连接的使用
讲解
什么是内连接
用左边表的记录去匹配右边表的记录,如果符合条件的则显示
隐式内连接
隐式内连接:看不到JOIN关键字,条件使用WHERE指定
SELECT 字段 FROM 左表, 右表 WHERE 条件;
显示内连接
显示内连接:使用INNER JOIN ... ON语句, 可以省略INNER
SELECT 字段 FROM 左表 INNER JOIN 右表 ON 条件;
SELECT 字段 FROM 左表 JOIN 右表 ON 条件;
具体操作:
- 查询唐僧的信息,显示员工id,姓名,性别,工资和所在的部门名称,我们发现需要联合2张表同时才能查询出需要的数据,我们使用内连接

- 确定查询哪些表
SELECT * FROM dept INNER JOIN emp;

- 确定表连接条件,员工表.dept_id = 部门表.id 的数据才是有效的
SELECT * FROM dept INNER JOIN emp ON emp.`dept_id`=dept.`id`;

- 确定查询条件,我们查询的是唐僧的信息,部门表.name='唐僧'
SELECT * FROM dept INNER JOIN emp ON emp.`dept_id`=dept.`id` AND emp.`NAME`='唐僧';

- 确定查询字段,查询唐僧的信息,显示员工id,姓名,性别,工资和所在的部门名称
SELECT emp.`id`, emp.`NAME`, emp.`gender`, emp.`salary`, dept.`NAME` FROM dept INNER JOIN emp ON emp.`dept_id`=dept.`id` AND emp.`NAME`='唐僧';

- 我们发现写表名有点长,可以给表取别名,显示的字段名也使用别名
SELECT e.`id` 员工编号, e.`NAME` 员工姓名, e.`gender` 性别, e.`salary` 工资, d.`NAME` 部门名称 FROM dept d INNER JOIN emp e ON e.`dept_id`=d.`id` AND e.`NAME`='唐僧';

小结
- 什么是隐式内连接和显示内连接? 隐式内连接:看不到JOIN:SELECT 字段 FROM 左表, 右表 WHERE 条件; 显示内连接:看得到JOIN:SELECT 字段 FROM 左表 INNER JOIN 右表 ON 条件;
- 内连接查询步骤? 1.确定查询几张表 2.确定表连接条件 3.根据需要在操作
左外连接
目标
能够掌握左外连接查询
讲解
左外连接:使用LEFT OUTER JOIN ... ON,OUTER可以省略
SELECT 字段名 FROM 左表 LEFT OUTTER JOIN 右表 ON 条件;
左外连接可以理解为:在内连接的基础上保证左表的数据全部显示,右表中没有对应的记录,使用NULL填充。
具体操作:
- 在部门表中增加一个销售部
INSERT INTO dept (NAME) VALUES ('销售部');

- 使用内连接查询
SELECT * FROM dept INNER JOIN emp ON emp.`dept_id`=dept.`id`;

- 使用左外连接查询
SELECT * FROM dept LEFT OUTER JOIN emp ON emp.`dept_id`=dept.`id`;

小结
-
掌握左外连接查询格式?
SELECT 字段 FROM 左表 LEFT OUTER JOIN 右表 ON 条件 -
左外连接查询特点? 在满足要求的基础上保证左表的数据全部显示 在内连接的基础上保证左表的数据全部显示
右外连接
目标
能够掌握右外连接查询
讲解
右外连接:使用RIGHT OUTER JOIN ... ON,OUTER可以省略
右外连接可以理解为:在内连接的基础上保证右表的数据全部显示,左表中没有对应的记录,使用NULL填充。
具体操作:
- 在员工表中增加一个员工
INSERT INTO emp(NAME,gender,salary,join_date,dept_id) VALUES('沙僧','男',6666,'2013-02-24',NULL);

- 使用内连接查询
SELECT * FROM dept INNER JOIN emp ON emp.`dept_id`=dept.`id`;
- 使用右外连接查询
SELECT * FROM dept RIGHT OUTER JOIN emp ON emp.`dept_id`=dept.`id`;

小结
-
掌握右外连接查询格式?
SELECT 字段 FROM 左表 RIGHT OUTER JOIN 右表 ON 条件; -
右外连接查询特点? 在满足要求的基础上,保证右表的数据全部显示.
子查询
目标
能够掌握子查询的概念
能够理解子查询的三种情况
讲解
什么是子查询
一条查询语句结果作为另一条查询语法一部分。
SELECT 查询字段 FROM 表 WHERE 条件;
SELECT * FROM employee WHERE salary=(SELECT MAX(salary) FROM employee);
 子查询需要放在()中
子查询需要放在()中
子查询结果的三种情况
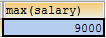
- 子查询的结果是单行单列的时候
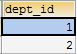
- 子查询的结果是多行单列的时候
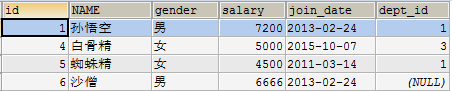
- 子查询的结果是多行多列



小结
- 什么是子查询? 一个查询的结果作为另一个查询语句的一部分
- 子查询结果的三种情况? 单行单列 多行单列 多行多列
子查询的结果是单行单列的时候
目标
能够掌握子查询的结果是单行单列的查询
讲解
子查询结果是单列,在WHERE后面作为条件
SELECT 查询字段 FROM 表 WHERE 字段=(子查询);
-
查询工资最高的员工是谁?
- 查询最高工资是多少
SELECT MAX(salary) FROM emp;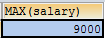
- 根据最高工资到员工表查询到对应的员工信息
SELECT * FROM emp WHERE salary=(SELECT MAX(salary) FROM emp);
-
查询工资小于平均工资的员工有哪些?
- 查询平均工资是多少
SELECT AVG(salary) FROM emp;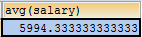
- 到员工表查询小于平均的员工信息
SELECT * FROM emp WHERE salary < (SELECT AVG(salary) FROM emp);




小结
子查询的结果是单行单列时父查询如何处理? SELECT 查询字段 FROM 表 WHERE 字段=(子查询);
通常作为父查询的条件
子查询结果是多行单列的时候
目标
能够掌握子查询的结果是多行单列的查询
讲解
子查询结果是单列多行,结果集类似于一个数组,在WHERE后面作为条件,父查询使用IN运算符
SELECT 查询字段 FROM 表 WHERE 字段 IN (子查询);
-
查询工资大于5000的员工,来自于哪些部门的名字
- 先查询大于5000的员工所在的部门id
SELECT dept_id FROM emp WHERE salary > 5000;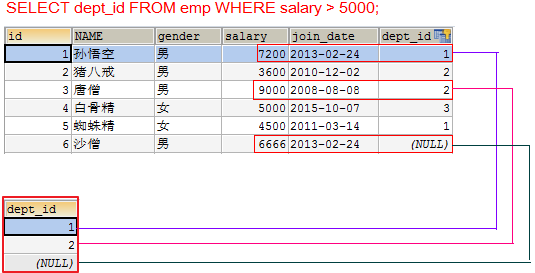
- 再查询在这些部门id中部门的名字
SELECT dept.name FROM dept WHERE dept.id IN (SELECT dept_id FROM emp WHERE salary > 5000);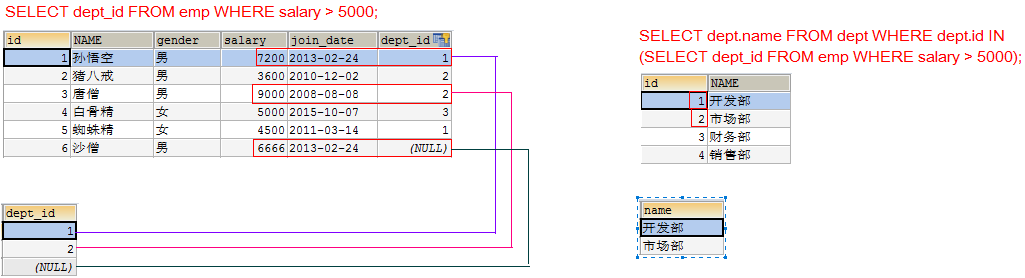
-
查询开发部与财务部所有的员工信息
- 先查询开发部与财务部的id
SELECT id FROM dept WHERE NAME IN('开发部','财务部');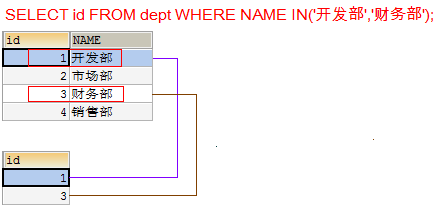
- 再查询在这些部门id中有哪些员工
SELECT * FROM emp WHERE dept_id IN (SELECT id FROM dept WHERE NAME IN('开发部','财务部'));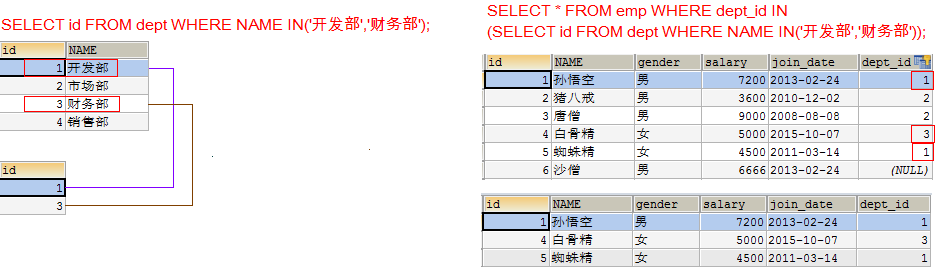




小结
子查询的结果是多行单列时父查询如何处理? 放在父查询的条件位置,使用in
子查询的结果是多行多列
目标
能够掌握子查询的结果是多行多列的查询
讲解
子查询结果是多列,在FROM后面作为表
SELECT 查询字段 FROM (子查询) 表别名 WHERE 条件;
子查询作为表需要取别名,否则这张表没用名称无法访问表中的字段
-
查询出2011年以后入职的员工信息,包括部门名称
- 在员工表中查询2011-1-1以后入职的员工
SELECT * FROM emp WHERE join_date > '2011-1-1';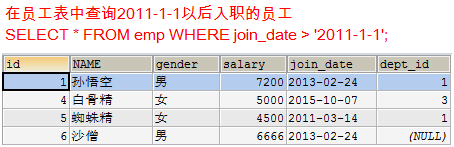
- 查询所有的部门信息,与上面的虚拟表中的信息组合,找出所有部门id等于dept_id
SELECT * FROM dept d, (SELECT * FROM emp WHERE join_date > '2011-1-1') e WHERE e.dept_id = d.id;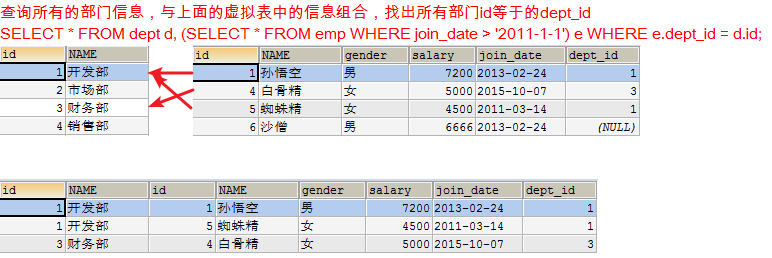


使用表连接:
SELECT d.*, e.* FROM dept d INNER JOIN emp e ON d.id = e.dept_id WHERE e.join_date > '2011-1-1';
小结
三种子查询情况:单行单列,多行单列,多行多列 单行单列:作为父查询的条件 多行单列:作为父查询的条件,通常使用 IN 多行多列:作为父查询的一张表(虚拟表)
第三章 事务的概念
目标
- 能够理解事务的概念
- 了解事务的四大特性
讲解
什么是事务
在实际的业务开发中,有些业务操作要多次访问数据库。一个业务要发送多条SQL语句给数据库执行。需要将多次访问数据库的操作视为一个整体来执行,要么所有的SQL语句全部执行成功。如果其中有一条SQL语句失败,就进行事务的回滚,所有的SQL语句全部执行失败。
事务的应用场景说明
例如: 张三给李四转账,张三账号减钱,李四账号加钱
-- 创建数据表
CREATE TABLE account (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(10),
balance DOUBLE
);
-- 添加数据
INSERT INTO account (NAME, balance) VALUES ('张三', 1000), ('李四', 1000);
模拟张三给李四转500元钱,一个转账的业务操作最少要执行下面的2条语句:
- 张三账号-500
- 李四账号+500
-- 1. 张三账号-500
UPDATE account SET balance = balance - 500 WHERE id=1;
-- 2. 李四账号+500
UPDATE account SET balance = balance + 500 WHERE id=2;
假设当张三账号上-500元,服务器崩溃了。李四的账号并没有+500元,数据就出现问题了。我们需要保证其中一条SQL语句出现问题,整个转账就算失败。只有两条SQL都成功了转账才算成功。这个时候就需要用到事务。
事务的四大特性(ACID)
| 事务特性 | 含义 |
|---|---|
| 原子性(Atomicity) | 事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。 |
| 一致性(Consistency) | 事务前后数据的完整性必须保持一致 |
| 隔离性(Isolation) | 是指多个用户并发访问数据库时,一个用户的事务不能被其它用户的事务所干扰,多个并发事务之间数据要相互隔离,不能相互影响。 |
| 持久性(Durability) | 指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响 |
小结
什么是事务?多条SQL组合再一起完成某个功能.
事务四个特性? 原子性 一致性 隔离性 持久性
手动提交事务
目标
能够使用手动的方式提交事务
讲解
MYSQL中可以有两种方式进行事务的操作:
- 手动提交事务
- 自动提交事务(默认的)
事务有关的SQL语句:
| SQL语句 | 描述 |
|---|---|
| start transaction; | 开启事务 |
| commit; | 提交事务 |
| rollback; | 回滚事务 |
手动提交事务使用步骤
第1种情况:开启事务 -> 执行SQL语句 -> 成功 -> 提交事务
第2种情况:开启事务 -> 执行SQL语句 -> 失败 -> 回滚事务

案例演示1:模拟张三给李四转500元钱(成功)
目前数据库数据如下:

- 使用DOS控制台进入MySQL
- 执行以下SQL语句:
1.开启事务,2.张三账号-500,3.李四账号+500START TRANSACTION; UPDATE account SET balance = balance - 500 WHERE id=1; UPDATE account SET balance = balance + 500 WHERE id=2;
- 使用SQLYog查看数据库:发现数据并没有改变

- 在控制台执行
commit提交任务: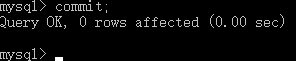
- 使用SQLYog查看数据库:发现数据改变



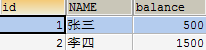
案例演示2:模拟张三给李四转500元钱(失败)
目前数据库数据如下:

- 在控制台执行以下SQL语句:
1.开启事务,2.张三账号-500START TRANSACTION; UPDATE account SET balance = balance - 500 WHERE id=1;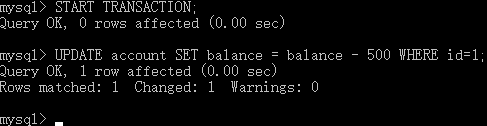
- 使用SQLYog查看数据库:发现数据并没有改变
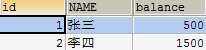
- 在控制台执行
rollback回滚事务: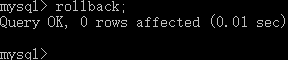
- 使用SQLYog查看数据库:发现数据没有改变




小结
- 如何开启事务: start transaction;
- 如何提交事务: commit;
- 如何回滚事务: rollback;
自动提交事务
目标
了解自动提交事务
能够关闭自动提交事务
讲解
MySQL的每一条DML(增删改)语句都是一个单独的事务,每条语句都会自动开启一个事务,执行完毕自动提交事务,MySQL默认开始自动提交事务。

-
将金额重置为1000
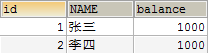
-
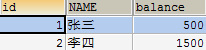
执行以下SQL语句
UPDATE account SET balance = balance - 500 WHERE id=1; -
使用SQLYog查看数据库:发现数据已经改变
使用SQL语句查看MySQL是否开启自动提交事务


show variables like '%commit%'; -- 或 SELECT @@autocommit;
通过修改MySQL全局变量"autocommit",取消自动提交事务

0:OFF(关闭自动提交)
1:ON(开启自动提交)
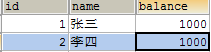
4. 取消自动提交事务,设置自动提交的参数为OFF,执行SQL语句:`set autocommit = 0;`

5. 在控制台执行以下SQL语句:张三-500
```sql
UPDATE account SET balance = balance - 500 WHERE id=1;

-
使用SQLYog查看数据库,发现数据并没有改变
-
在控制台执行
commit提交任务
-
使用SQLYog查看数据库,发现数据改变
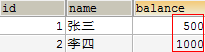



小结
- 查询事务提交状态: show variables like '%commit%'; select @@autocommit;
- 关闭事务自动提交: set autocommit = 0;
总结
-
能够理解三大范式 1NF: 表中的字段不能再拆分 2NF:一个表做一件事情,表中添加主键,所有字段依赖主键 3NF:多张表之间使用其他表的主键
-
能够使用内连接进行多表查询 隐式: SELECT 字段 FROM 左表, 右表 WHERE 条件;
显示: SELECT 字段 FROM 左表 INNER JOIN 右表 ON 条件;
-
能够使用左外连接和右外连接进行多表查询 左外连接: SELECT 字段 FROM 左表 LEFT OUTER JOIN 右表 ON 条件; 右外连接: SELECT 字段 FROM 左表 RIGHT OUTER JOIN 右表 ON 条件;
-
能够使用子查询进行多表查询 SELECT 字段 FROM 表名 WHERE 字段=(SELECT MAX(age) FROM 表名);
-
能够理解多表查询的规律 1.明确查询哪些表 2.明确表之间的连接条件,外键=主键 3.根据需求
-
能够理解事务的概念 多条SQL语句组成一个功能,要么一起成功,要么一起失败.
-
能够在MySQL中使用事务 开启事务: start transaction; 提交事务: commit; 回滚事务: rollback; 查看是否自动提交事务: show variables like '%commit%'; 关闭事务自动提交: set autocommit = 0;