36 KiB
SQLAlchemy
1. MySQL数据库
在网站开发中,数据库是网站的重要组成部分。只有提供数据库,数据才能够动态的展示,而不是在网页中显示一个静态的页面。数据库有很多,比如有SQL Server、Oracle、PostgreSQL以及MySQL等等。MySQL由于价格实惠、简单易用、不受平台限制、灵活度高等特性,目前已经取得了绝大多数的市场份额。因此我们在Flask中,也是使用MySQL来作为数据存储。
1.1 MySQL数据库安装
- 在
MySQL的官网下载MySQL数据库安装文件:https://dev.mysql.com/downloads/mysql/。 - 然后双击安装,如果出现以下错误,则到
http://www.microsoft.com/en-us/download/details.aspx?id=17113下载.net framework。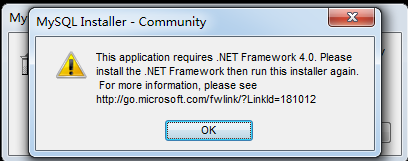
- 在安装过程中,如果提示没有
Microsoft C++ 2013,那么就到以下网址下载安装即可:http://download.microsoft.com/download/9/0/5/905DBD86-D1B8-4D4B-8A50-CB0E922017B9/vcredist_x64.exe。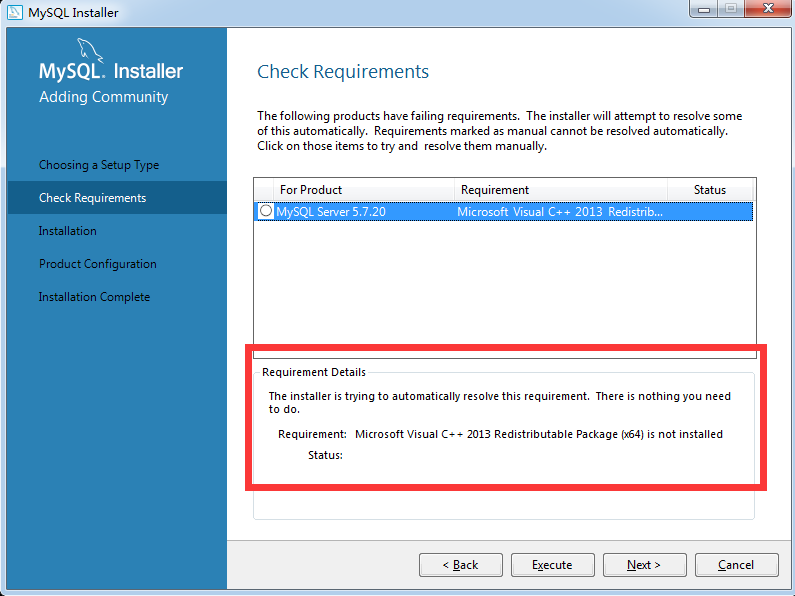
- 接下来就是做好用户名和密码的配置即可。


1.2 navicat数据库操作软件
安装完MySQL数据库以后,就可以使用MySQL提供的终端客户端软件来操作数据库。如下:
 这个软件所有的操作都是基于
这个软件所有的操作都是基于sql语言,对于想要熟练sql语言的同学来讲是非常合适的。但是对于在企业中可能不是一款好用的工具。在企业中我们推荐使用mysql workbench以及navicat这种图形化操作的软件。而mysql workbench是mysql官方提供的一个免费的软件,正因为是免费,所以在一些功能上不及navicat。navicat for mysql是一款收费的软件。官网地址如下:https://www.navicat.com.cn/products。使用的截图如下:

1.3 MySQL驱动程序安装
我们使用Django来操作MySQL,实际上底层还是通过Python来操作的。因此我们想要用Flask来操作MySQL,首先还是需要安装一个驱动程序。在Python3中,驱动程序有多种选择。比如有pymysql以及mysqlclient等。这里我们就使用mysqlclient来操作。mysqlclient安装非常简单。只需要通过pip install mysqlclient即可安装。
常见MySQL驱动介绍:
MySQL-python:也就是MySQLdb。是对C语言操作MySQL数据库的一个简单封装。遵循了Python DB API v2。但是只支持Python2,目前还不支持Python3。mysqlclient:是MySQL-python的另外一个分支。支持Python3并且修复了一些bug。pymysql:纯Python实现的一个驱动。因为是纯Python编写的,因此执行效率不如MySQL-python。并且也因为是纯Python编写的,因此可以和Python代码无缝衔接。MySQL Connector/Python:MySQL官方推出的使用纯Python连接MySQL的驱动。因为是纯Python开发的。效率不高。
2. SQLAlchemy介绍
2.1 安装:
SQLAlchemy是一个数据库的ORM框架,让我们操作数据库的时候不要再用SQL语句了,跟直接操作模型一样。安装命令为:pip install SQLAlchemy。
2.2 通过SQLAlchemy连接数据库:
首先来看一段代码:
from sqlalchemy import create_engine
# 数据库的配置变量
HOSTNAME = '127.0.0.1'
PORT = '3306'
DATABASE = 'xt_flask'
USERNAME = 'root'
PASSWORD = 'root'
DB_URI = 'mysql+pymysql://{}:{}@{}:{}/{}'.format(USERNAME,PASSWORD,HOSTNAME,PORT,DATABASE)
# 创建数据库引擎
engine = create_engine(DB_URI)
#创建连接
with engine.connect() as con:
rs = con.execute('SELECT 1')
print rs.fetchone()
首先从sqlalchemy中导入create_engine,用这个函数来创建引擎,然后用engine.connect()来连接数据库。其中一个比较重要的一点是,通过create_engine函数的时候,需要传递一个满足某种格式的字符串,对这个字符串的格式来进行解释:
dialect+driver://username:password@host:port/database?charset=utf8
dialect是数据库的实现,比如MySQL、PostgreSQL、SQLite,并且转换成小写。driver是Python对应的驱动,如果不指定,会选择默认的驱动,比如MySQL的默认驱动是MySQLdb。username是连接数据库的用户名,password是连接数据库的密码,host是连接数据库的域名,port是数据库监听的端口号,database是连接哪个数据库的名字。
如果以上输出了1,说明SQLAlchemy能成功连接到数据库。
2.3 用SQLAlchemy执行原生SQL:
我们将上一个例子中的数据库配置选项单独放在一个constants.py的文件中,看以下例子:
from sqlalchemy import create_engine
from constants import DB_URI
#连接数据库
engine = create_engine(DB_URI,echo=True)
# 使用with语句连接数据库,如果发生异常会被捕获
with engine.connect() as con:
# 先删除users表
con.execute('drop table if exists authors')
# 创建一个users表,有自增长的id和name
con.execute('create table authors(id int primary key auto_increment,'name varchar(25))')
# 插入两条数据到表中
con.execute('insert into persons(name) values("abc")')
con.execute('insert into persons(name) values("xiaotuo")')
# 执行查询操作
results = con.execute('select * from persons')
# 从查找的结果中遍历
for result in results:
print(result)
3. SQLAlchemy基本使用
3.1 使用SQLAlchemy:
3.1.1 创建ORM模型:
要使用ORM来操作数据库,首先需要创建一个类来与对应的表进行映射。现在以User表来做为例子,它有自增长的id、name、fullname、password这些字段,那么对应的类为:
from sqlalchemy import Column,Integer,String
from constants import DB_URI
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
engine = create_engine(DB_URI,echo=True)
# 所有的类都要继承自`declarative_base`这个函数生成的基类
Base = declarative_base(engine)
class User(Base):
# 定义表名为users
__tablename__ = 'users'
# 将id设置为主键,并且默认是自增长的
id = Column(Integer,primary_key=True)
# name字段,字符类型,最大的长度是50个字符
name = Column(String(50))
fullname = Column(String(50))
password = Column(String(100))
# 让打印出来的数据更好看,可选的
def __repr__(self):
return "<User(id='%s',name='%s',fullname='%s',password='%s')>" % (self.id,self.name,self.fullname,self.password)
3.1.2 映射到数据库中:
SQLAlchemy会自动的设置第一个Integer的主键并且没有被标记为外键的字段添加自增长的属性。因此以上例子中id自动的变成自增长的。以上创建完和表映射的类后,还没有真正的映射到数据库当中,执行以下代码将类映射到数据库中:
Base.metadata.create_all()
3.1.3 添加数据到表中:
在创建完数据表,并且做完和数据库的映射后,接下来让我们添加数据进去:
ed_user = User(name='ed',fullname='Ed Jones',password='edspassword')
# 打印名字
print ed_user.name
> ed
# 打印密码
print ed_user.password
> edspassword
# 打印id
print(ed_user.id)
> None
可以看到,name和password都能正常的打印,唯独id为None,这是因为id是一个自增长的主键,还未插入到数据库中,id是不存在的。接下来让我们把创建的数据插入到数据库中。和数据库打交道的,是一个叫做Session的对象:
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
# 或者
# Session = sessionmaker()
# Session.configure(bind=engine)
session = Session()
ed_user = User(name='ed',fullname='Ed Jones',password='edspassword')
session.add(ed_user)
现在只是把数据添加到session中,但是并没有真正的把数据存储到数据库中。如果需要把数据存储到数据库中,还要做一次commit操作:
session.commit()
# 打印ed_user的id
print ed_user.id
> 1
3.1.4 回滚:
这时候,ed_user就已经有id。 说明已经插入到数据库中了。有人肯定有疑问了,为什么添加到session中后还要做一次commit操作呢,这是因为,在SQLAlchemy的ORM实现中,在做commit操作之前,所有的操作都是在事务中进行的,因此如果你要将事务中的操作真正的映射到数据库中,还需要做commit操作。既然用到了事务,这里就并不能避免的提到一个回滚操作了,那么看以下代码展示了如何使用回滚(接着以上示例代码):
# 修改ed_user的用户名
ed_user.name = 'Edwardo'
# 创建一个新的用户
fake_user = User(name='fakeuser',fullname='Invalid',password='12345')
# 将新创建的fake_user添加到session中
session.add(fake_user)
# 判断`fake_user`是否在`session`中存在
print fake_user in session
> True
# 从数据库中查找name=Edwardo的用户
tmp_user = session.query(User).filter_by(name='Edwardo')
# 打印tmp_user的name
print tmp_user
# 打印出查找到的tmp_user对象,注意这个对象的name属性已经在事务中被修改为Edwardo了。
> <User(name='Edwardo', fullname='Ed Jones', password='edspassword')>
# 刚刚所有的操作都是在事务中进行的,现在来做回滚操作
session.rollback()
# 再打印tmp_user
print tmp_user
> <User(name='ed', fullname='Ed Jones', password='edspassword')>
# 再看fake_user是否还在session中
print fake_user in session
> False
3.1.5 查找数据:
接下来看下如何进行查找操作,查找操作是通过session.query()方法实现的,这个方法会返回一个Query对象,Query对象相当于一个数组,装载了查找出来的数据,并且可以进行迭代。具体里面装的什么数据,就要看向session.query()方法传的什么参数了,如果只是传一个ORM的类名作为参数,那么提取出来的数据就是都是这个类的实例,比如:
for instance in session.query(User).order_by(User.id):
print instance
# 输出所有的user实例
> <User (id=2,name='ed',fullname='Ed Json',password='12345')>
> <User (id=3,name='be',fullname='Be Engine',password='123456')>
如果传递了两个及其两个以上的对象,或者是传递的是ORM类的属性,那么查找出来的就是元组,例如:
for instance in session.query(User.name):
print instance
# 输出所有的查找结果
> ('ed',)
> ('be',)
以及:
for instance in session.query(User.name,User.fullname):
print instance
# 输出所有的查找结果
> ('ed', 'Ed Json')
> ('be', 'Be Engine')
或者是:
for instance in session.query(User,User.name).all():
print instance
# 输出所有的查找结果
> (<User (id=2,name='ed',fullname='Ed Json',password='12345')>, 'Ed Json')
> (<User (id=3,name='be',fullname='Be Engine',password='123456')>, 'Be Engine')
另外,还可以对查找的结果(Query)做切片操作:
for instance in session.query(User).order_by(User.id)[1:3]
instance
如果想对结果进行过滤,可以使用filter_by和filter两个方法,这两个方法都是用来做过滤的,区别在于,filter_by是传入关键字参数,filter是传入条件判断,并且filter能够传入的条件更多更灵活,请看以下例子:
# 第一种:使用filter_by过滤:
for name in session.query(User.name).filter_by(fullname='Ed Jones'):
print name
# 输出结果:
> ('ed',)
# 第二种:使用filter过滤:
for name in session.query(User.name).filter(User.fullname=='Ed Jones'):
print name
# 输出结果:
> ('ed',)
3.2 Column常用参数:
default:默认值。nullable:是否可空。primary_key:是否为主键。unique:是否唯一。autoincrement:是否自动增长。onupdate:更新的时候执行的函数。name:该属性在数据库中的字段映射。
3.3 sqlalchemy常用数据类型:
Integer:整形。Float:浮点类型。Boolean:传递True/False进去。DECIMAL:定点类型。enum:枚举类型。Date:传递datetime.date()进去。DateTime:传递datetime.datetime()进去。Time:传递datetime.time()进去。String:字符类型,使用时需要指定长度,区别于Text类型。Text:文本类型。LONGTEXT:长文本类型。
4. 查找操作
4.1 query可用参数:
- 模型对象。指定查找这个模型中所有的对象。
- 模型中的属性。可以指定只查找某个模型的其中几个属性。
- 聚合函数。
func.count:统计行的数量。func.avg:求平均值。func.max:求最大值。func.min:求最小值。func.sum:求和。
4.2 过滤条件:
过滤是数据提取的一个很重要的功能,以下对一些常用的过滤条件进行解释,并且这些过滤条件都是只能通过filter方法实现的:
equals:
query.filter(User.name == 'ed')
not equals:
query.filter(User.name != 'ed')
like:
query.filter(User.name.like('%ed%'))
in:
query.filter(User.name.in_(['ed','wendy','jack']))
# 同时,in也可以作用于一个Query
query.filter(User.name.in_(session.query(User.name).filter(User.name.like('%ed%'))))
not in:
query.filter(~User.name.in_(['ed','wendy','jack']))
is null:
query.filter(User.name==None)
# 或者是
query.filter(User.name.is_(None))
is not null:
query.filter(User.name != None)
# 或者是
query.filter(User.name.isnot(None))
and:
from sqlalchemy import and_
query.filter(and_(User.name=='ed',User.fullname=='Ed Jones'))
# 或者是传递多个参数
query.filter(User.name=='ed',User.fullname=='Ed Jones')
# 或者是通过多次filter操作
query.filter(User.name=='ed').filter(User.fullname=='Ed Jones')
or:
from sqlalchemy import or_ query.filter(or_(User.name=='ed',User.name=='wendy'))
4.3 查找方法:
介绍完过滤条件后,有一些经常用到的查找数据的方法也需要解释一下:
all():返回一个Python列表(list):
query = session.query(User).filter(User.name.like('%ed%').order_by(User.id)
# 输出query的类型
print type(query)
> <type 'list'>
# 调用all方法
query = query.all()
# 输出query的类型
print type(query)
> <class 'sqlalchemy.orm.query.Query'>
first():返回Query中的第一个值:
user = session.query(User).first()
print user
> <User(name='ed', fullname='Ed Jones', password='f8s7ccs')>
one():查找所有行作为一个结果集,如果结果集中只有一条数据,则会把这条数据提取出来,如果这个结果集少于或者多于一条数据,则会抛出异常。总结一句话:有且只有一条数据的时候才会正常的返回,否则抛出异常:
# 多于一条数据
user = query.one()
> Traceback (most recent call last):
> ...
> MultipleResultsFound: Multiple rows were found for one()
# 少于一条数据
user = query.filter(User.id == 99).one()
> Traceback (most recent call last):
> ...
> NoResultFound: No row was found for one()
# 只有一条数据
> query(User).filter_by(name='ed').one()
-
one_or_none():跟one()方法类似,但是在结果集中没有数据的时候也不会抛出异常。 -
scalar():底层调用one()方法,并且如果one()方法没有抛出异常,会返回查询到的第一列的数据:
session.query(User.name,User.fullname).filter_by(name='ed').scalar()
4.4 文本SQL:
SQLAlchemy还提供了使用文本SQL的方式来进行查询,这种方式更加的灵活。而文本SQL要装在一个text()方法中,看以下例子:
from sqlalchemy import text
for user in session.query(User).filter(text("id<244")).order_by(text("id")).all():
print user.name
如果过滤条件比如上例中的244存储在变量中,这时候就可以通过传递参数的形式进行构造:
session.query(User).filter(text("id<:value and name=:name")).params(value=224,name='ed').order_by(User.id)
在文本SQL中的变量前面使用了:来区分,然后使用params方法,指定需要传入进去的参数。另外,使用from_statement方法可以把过滤的函数和条件函数都给去掉,使用纯文本的SQL:
sesseion.query(User).from_statement(text("select * from users where name=:name")).params(name='ed').all()
使用from_statement方法一定要注意,from_statement返回的是一个text里面的查询语句,一定要记得调用all()方法来获取所有的值。
4.5 计数(Count):
Query对象有一个非常方便的方法来计算里面装了多少数据:
session.query(User).filter(User.name.like('%ed%')).count()
当然,有时候你想明确的计数,比如要统计users表中有多少个不同的姓名,那么简单粗暴的采用以上count是不行的,因为姓名有可能会重复,但是处于两条不同的数据上,如果在原生数据库中,可以使用distinct关键字,那么在SQLAlchemy中,可以通过func.count()方法来实现:
from sqlalchemy import func
session.query(func.count(User.name),User.name).group_by(User.name).all()
## 输出的结果
> [(1, u'ed'), (1, u'fred'), (1, u'mary'), (1, u'wendy')]
另外,如果想实现select count(*) from users,可以通过以下方式来实现:
session.query(func.count(*)).select_from(User).scalar()
当然,如果指定了要查找的表的字段,可以省略select_from()方法:
session.query(func.count(User.id)).scalar()
5. 表关系:
表之间的关系存在三种:一对一、一对多、多对多。而SQLAlchemy中的ORM也可以模拟这三种关系。因为一对一其实在SQLAlchemy中底层是通过一对多的方式模拟的,所以先来看下一对多的关系:
5.1 外键:
在Mysql中,外键可以让表之间的关系更加紧密。而SQLAlchemy同样也支持外键。通过ForeignKey类来实现,并且可以指定表的外键约束。相关示例代码如下:
class Article(Base):
__tablename__ = 'article'
id = Column(Integer,primary_key=True,autoincrement=True)
title = Column(String(50),nullable=False)
content = Column(Text,nullable=False)
uid = Column(Integer,ForeignKey('user.id'))
def __repr__(self):
return "<Article(title:%s)>" % self.title
class User(Base):
__tablename__ = 'user'
id = Column(Integer,primary_key=True,autoincrement=True)
username = Column(String(50),nullable=False)
外键约束有以下几项:
RESTRICT:父表数据被删除,会阻止删除。默认就是这一项。NO ACTION:在MySQL中,同RESTRICT。CASCADE:级联删除。SET NULL:父表数据被删除,子表数据会设置为NULL。
5.2 一对多:
拿之前的User表为例,假如现在要添加一个功能,要保存用户的邮箱帐号,并且邮箱帐号可以有多个,这时候就必须创建一个新的表,用来存储用户的邮箱,然后通过user.id来作为外键进行引用,先来看下邮箱表的实现:
from sqlalchemy import ForeignKey
from sqlalchemy.orm import relationship
class Address(Base):
__tablename__ = 'address'
id = Column(Integer,primary_key=True)
email_address = Column(String,nullable=False)
# User表的外键,指定外键的时候,是使用的是数据库表的名称,而不是类名
user_id = Column(Integer,ForeignKey('users.id'))
# 在ORM层面绑定两者之间的关系,第一个参数是绑定的表的类名,
# 第二个参数back_populates是通过User反向访问时的字段名称
user = relationship('User',back_populates="addresses")
def __repr__(self):
return "<Address(email_address='%s')>" % self.email_address
# 重新修改User表,添加了addresses字段,引用了Address表的主键
class User(Base):
__tablename__ = 'users'
id = Column(Integer,primary_key=True)
name = Column(String(50))
fullname = Column(String(50))
password = Column(String(100))
# 在ORM层面绑定和`Address`表的关系
addresses = relationship("Address",order_by=Address.id,back_populates="user")
其中,在User表中添加的addresses字段,可以通过User.addresses来访问和这个user相关的所有address。在Address表中的user字段,可以通过Address.user来访问这个user。达到了双向绑定。表关系已经建立好以后,接下来就应该对其进行操作,先看以下代码:
jack = User(name='jack',fullname='Jack Bean',password='gjffdd')
jack.addresses = [Address(email_address='jack@google.com'),
Address(email_address='j25@yahoo.com')]
session.add(jack)
session.commit()
首先,创建一个用户,然后对这个jack用户添加两个邮箱,最后再提交到数据库当中,可以看到这里操作Address并没有直接进行保存,而是先添加到用户里面,再保存。
5.3 一对一:
一对一其实就是一对多的特殊情况,从以上的一对多例子中不难发现,一对应的是User表,而多对应的是Address,也就是说一个User对象有多个Address。因此要将一对多转换成一对一,只要设置一个User对象对应一个Address对象即可,看以下示例:
class User(Base):
__tablename__ = 'users'
id = Column(Integer,primary_key=True)
name = Column(String(50))
fullname = Column(String(50))
password = Column(String(100))
# 设置uselist关键字参数为False
addresses = relationship("Address",back_populates='addresses',uselist=False)
class Address(Base):
__tablename__ = 'addresses'
id = Column(Integer,primary_key=True)
email_address = Column(String(50))
user_id = Column(Integer,ForeignKey('users.id')
user = relationship('Address',back_populates='user')
从以上例子可以看到,只要在User表中的addresses字段上添加uselist=False就可以达到一对一的效果。设置了一对一的效果后,就不能添加多个邮箱到user.addresses字段了,只能添加一个:
user.addresses = Address(email_address='ed@google.com')
5.4 多对多:
多对多需要一个中间表来作为连接,同理在sqlalchemy中的orm也需要一个中间表。假如现在有一个Teacher和一个Classes表,即老师和班级,一个老师可以教多个班级,一个班级有多个老师,是一种典型的多对多的关系,那么通过sqlalchemy的ORM的实现方式如下:
association_table = Table('teacher_classes',Base.metadata,
Column('teacher_id',Integer,ForeignKey('teacher.id')),
Column('classes_id',Integer,ForeignKey('classes.id'))
)
class Teacher(Base):
__tablename__ = 'teacher'
id = Column(Integer,primary_key=True)
tno = Column(String(10))
name = Column(String(50))
age = Column(Integer)
classes = relationship('Classes',secondary=association_table,back_populates='teachers')
class Classes(Base):
__tablename__ = 'classes'
id = Column(Integer,primary_key=True)
cno = Column(String(10))
name = Column(String(50))
teachers = relationship('Teacher',secondary=association_table,back_populates='classes')
要创建一个多对多的关系表,首先需要一个中间表,通过Table来创建一个中间表。上例中第一个参数teacher_classes代表的是中间表的表名,第二个参数是Base的元类,第三个和第四个参数就是要连接的两个表,其中Column第一个参数是表示的是连接表的外键名,第二个参数表示这个外键的类型,第三个参数表示要外键的表名和字段。
创建完中间表以后,还需要在两个表中进行绑定,比如在Teacher中有一个classes属性,来绑定Classes表,并且通过secondary参数来连接中间表。同理,Classes表连接Teacher表也是如此。定义完类后,之后就是添加数据,请看以下示例:
teacher1 = Teacher(tno='t1111',name='xiaotuo',age=10)
teacher2 = Teacher(tno='t2222',name='datuo',age=10)
classes1 = Classes(cno='c1111',name='english')
classes2 = Classes(cno='c2222',name='math')
teacher1.classes = [classes1,classes2]
teacher2.classes = [classes1,classes2]
classes1.teachers = [teacher1,teacher2]
classes2.teachers = [teacher1,teacher2]
session.add(teacher1)
session.add(teacher2)
session.add(classes1)
session.add(classes2)
5.5 ORM层面的CASCADE:
如果将数据库的外键设置为RESTRICT,那么在ORM层面,删除了父表中的数据,那么从表中的数据将会NULL。如果不想要这种情况发生,那么应该将这个值的nullable=False。
在SQLAlchemy,只要将一个数据添加到session中,和他相关联的数据都可以一起存入到数据库中了。这些是怎么设置的呢?其实是通过relationship的时候,有一个关键字参数cascade可以设置这些属性:
save-update:默认选项。在添加一条数据的时候,会把其他和他相关联的数据都添加到数据库中。这种行为就是save-update属性影响的。delete:表示当删除某一个模型中的数据的时候,是否也删掉使用relationship和他关联的数据。delete-orphan:表示当对一个ORM对象解除了父表中的关联对象的时候,自己便会被删除掉。当然如果父表中的数据被删除,自己也会被删除。这个选项只能用在一对多上,不能用在多对多以及多对一上。并且还需要在子模型中的relationship中,增加一个single_parent=True的参数。merge:默认选项。当在使用session.merge,合并一个对象的时候,会将使用了relationship相关联的对象也进行merge操作。expunge:移除操作的时候,会将相关联的对象也进行移除。这个操作只是从session中移除,并不会真正的从数据库中删除。all:是对save-update, merge, refresh-expire, expunge, delete几种的缩写。
6. 查询高级
6.1 排序:
-
order_by:可以指定根据这个表中的某个字段进行排序,如果在前面加了一个-,代表的是降序排序。 -
在模型定义的时候指定默认排序:有些时候,不想每次在查询的时候都指定排序的方式,可以在定义模型的时候就指定排序的方式。有以下两种方式:
-
relationship的order_by参数:在指定
relationship的时候,传递order_by参数来指定排序的字段。 -
在模型定义中,添加以下代码:
__mapper_args__ = { "order_by": title }即可让文章使用标题来进行排序。
-
-
正向排序和反向排序:默认情况是从小到大,从前到后排序的,如果想要反向排序,可以调用排序的字段的
desc方法。
6.2 limit、offset和切片:
limit:可以限制每次查询的时候只查询几条数据。offset:可以限制查找数据的时候过滤掉前面多少条。- 切片:可以对
Query对象使用切片操作,来获取想要的数据。
6.3 懒加载:
在一对多,或者多对多的时候,如果想要获取多的这一部分的数据的时候,往往能通过一个属性就可以全部获取了。比如有一个作者,想要或者这个作者的所有文章,那么可以通过user.articles就可以获取所有的。但有时候我们不想获取所有的数据,比如只想获取这个作者今天发表的文章,那么这时候我们可以给relationship传递一个lazy='dynamic',以后通过user.articles获取到的就不是一个列表,而是一个AppendQuery对象了。这样就可以对这个对象再进行一层过滤和排序等操作。
6.4 查询高级:
- group_by:
根据某个字段进行分组。比如想要根据性别进行分组,来统计每个分组分别有多少人,那么可以使用以下代码来完成:
session.query(User.gender,func.count(User.id)).group_by(User.gender).all()
- having:
having是对查找结果进一步过滤。比如只想要看未成年人的数量,那么可以首先对年龄进行分组统计人数,然后再对分组进行having过滤。示例代码如下:
result = session.query(User.age,func.count(User.id)).group_by(User.age).having(User.age >= 18).all()
- join方法:
join查询分为两种,一种是inner join,另一种是outer join。默认的是inner join,如果指定left join或者是right join则为outer join。如果想要查询User及其对应的Address,则可以通过以下方式来实现:
for u,a in session.query(User,Address).filter(User.id==Address.user_id).all():
print(u)
print(a)
# 输出结果:
> <User (id=1,name='ed',fullname='Ed Jason',password='123456')>
> <Address id=4,email=ed@google.com,user_id=1>
这是通过普通方式的实现,也可以通过join的方式实现,更加简单:
for u,a in session.query(User,Address).join(Address).all():
print(u)
print(a)
# 输出结果:
> <User (id=1,name='ed',fullname='Ed Jason',password='123456')>
> <Address id=4,email=ed@google.com,user_id=1>
当然,如果采用outerjoin,可以获取所有user,而不用在乎这个user是否有address对象,并且outerjoin默认为左外查询:
for instance in session.query(User,Address).outerjoin(Address).all():
print(instance)
# 输出结果:
(<User (id=1,name='ed',fullname='Ed Jason',password='123456')>, <Address id=4,email=ed@google.com,user_id=1>)
(<User (id=2,name='xt',fullname='xiaotuo',password='123')>, None)
- 别名:
当多表查询的时候,有时候同一个表要用到多次,这时候用别名就可以方便的解决命名冲突的问题了:
from sqlalchemy.orm import aliased
adalias1 = aliased(Address)
adalias2 = aliased(Address)
for username,email1,email2 in session.query(User.name,adalias1.email_address,adalias2.email_address).join(adalias1).join(adalias2).all():
print(username,email1,email2)
- 子查询:
sqlalchemy也支持子查询,比如现在要查找一个用户的用户名以及该用户的邮箱地址数量。要满足这个需求,可以在子查询中找到所有用户的邮箱数(通过group by合并同一用户),然后再将结果放在父查询中进行使用:
from sqlalchemy.sql import func
# 构造子查询
stmt = session.query(Address.user_id.label('user_id'),func.count(*).label('address_count')).group_by(Address.user_id).subquery()
# 将子查询放到父查询中
for u,count in session.query(User,stmt.c.address_count).outerjoin(stmt,User.id==stmt.c.user_id).order_by(User.id):
print(u,count)
从上面我们可以看到,一个查询如果想要变为子查询,则是通过subquery()方法实现,变成子查询后,通过子查询.c属性来访问查询出来的列。以上方式只能查询某个对象的具体字段,如果要查找整个实体,则需要通过aliased方法,示例如下:
stmt = session.query(Address)
adalias = aliased(Address,stmt)
for user,address in session.query(User,stmt).join(stmt,User.addresses):
print(user,address)
7. Flask-SQLAlchemy库
另外一个库,叫做Flask-SQLAlchemy,Flask-SQLAlchemy是对SQLAlchemy进行了一个简单的封装,使得我们在flask中使用sqlalchemy更加的简单。可以通过pip install flask-sqlalchemy。使用Flask-SQLAlchemy的流程如下:
- 数据库初始化:数据库初始化不再是通过
create_engine,请看以下示例:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from constants import DB_URI
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = DB_URI
db = SQLAlchemy(app)
ORM类:之前都是通过Base = declarative_base()来初始化一个基类,然后再继承,在Flask-SQLAlchemy中更加简单了(代码依赖以上示例):
class User(db.Model):
id = db.Column(db.Integer,primary_key=True)
username = db.Column(db.String(80),unique=True)
email = db.Column(db.String(120),unique=True)
def __init__(self,username,email):
self.username = username
self.email = email
def __repr__(self):
return '<User %s>' % self.username
- 映射模型到数据库表:使用
Flask-SQLAlchemy所有的类都是继承自db.Model,并且所有的Column和数据类型也都成为db的一个属性。但是有个好处是不用写表名了,Flask-SQLAlchemy会自动将类名小写化,然后映射成表名。 写完类模型后,要将模型映射到数据库的表中,使用以下代码创建所有的表:
db.create_all()
- 添加数据:这时候就可以在数据库中看到已经生成了一个
user表了。接下来添加数据到表中:
admin = User('admin','admin@example.com')
guest = User('guest','guest@example.com')
db.session.add(admin)
db.session.add(guest)
db.session.commit()
添加数据和之前的没有区别,只是session成为了一个db的属性。
- 查询数据:查询数据不再是之前的
session.query了,而是将query属性放在了db.Model上,所以查询就是通过Model.query的方式进行查询了:
users = User.query.all()
# 再如:
admin = User.query.filter_by(username='admin').first()
# 或者:
admin = User.query.filter(User.username='admin').first()
- 删除数据:删除数据跟添加数据类似,只不过
session是db的一个属性而已:
db.session.delete(admin)
db.session.commit()
8. MySQL8图文教程
8.1 下载:
在以下链接中下载MySQL8 Community:https://dev.mysql.com/downloads/windows/installer/8.0.html

8.2 安装:
下载完成后,就可以双击msi文件进行安装了。安装步骤如下。
- 第一步:选择
Developer Default: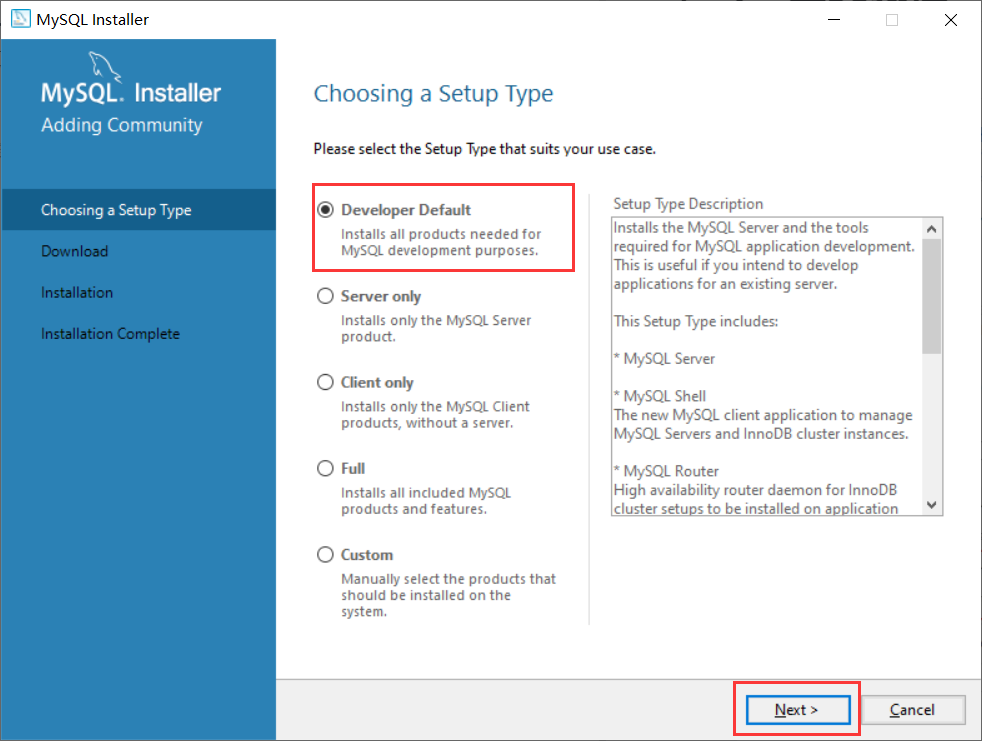
- 点击Execute:
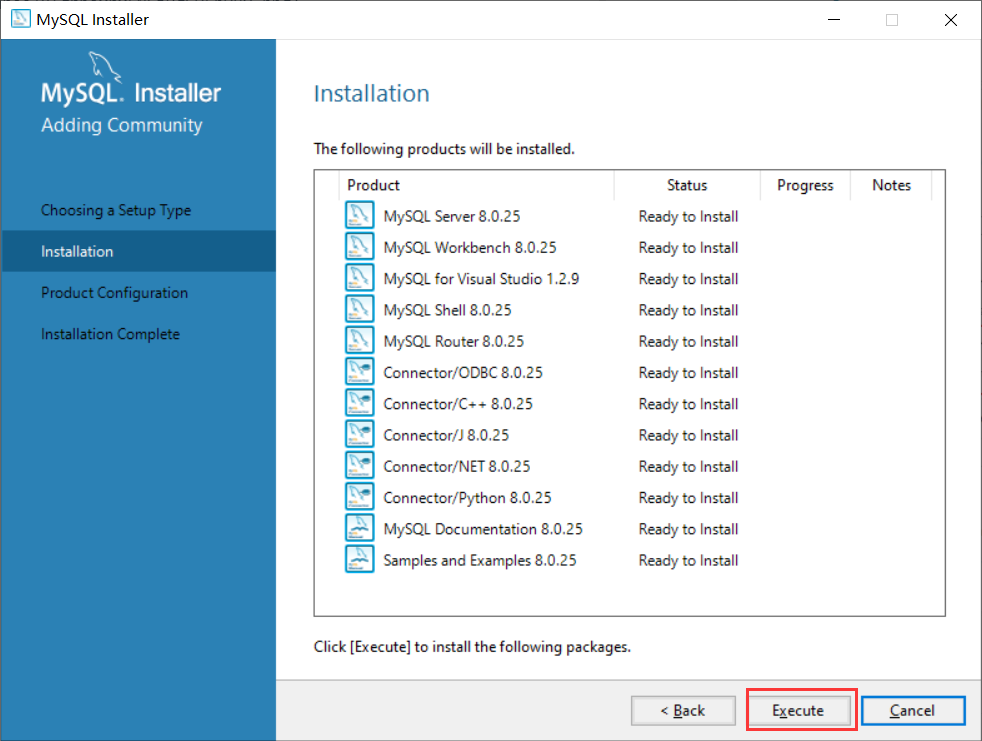 然后再点击
然后再点击Next执行下一步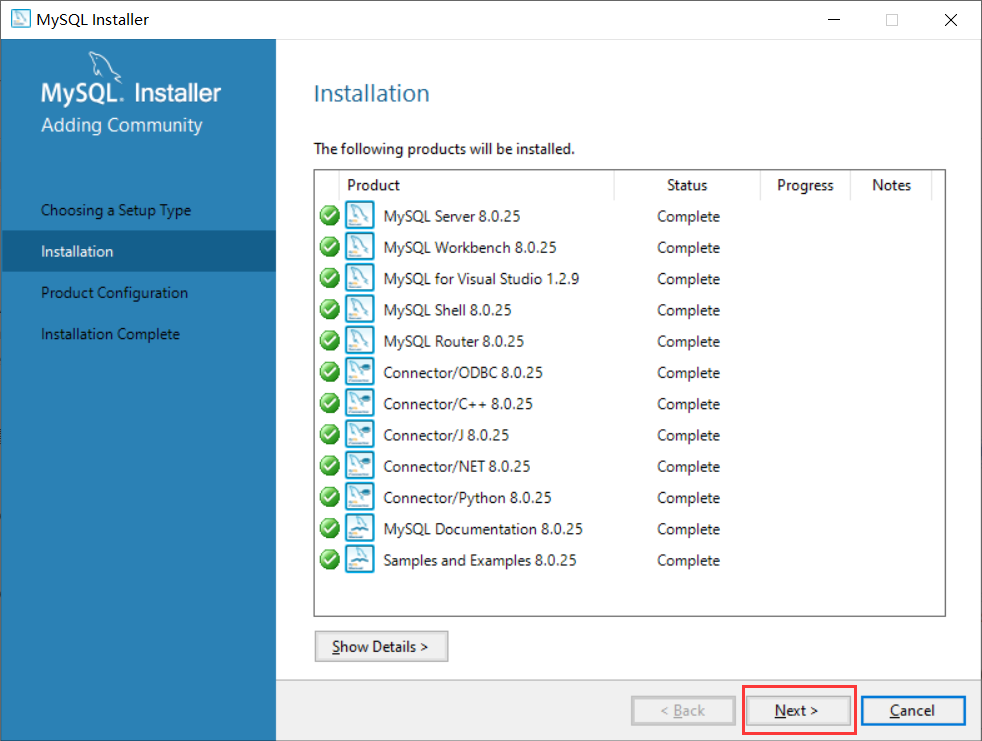
- 点击Next:
- 保持默认值,点击Next:
- 设置密码加密方式,用默认的即可,然后点击Next:
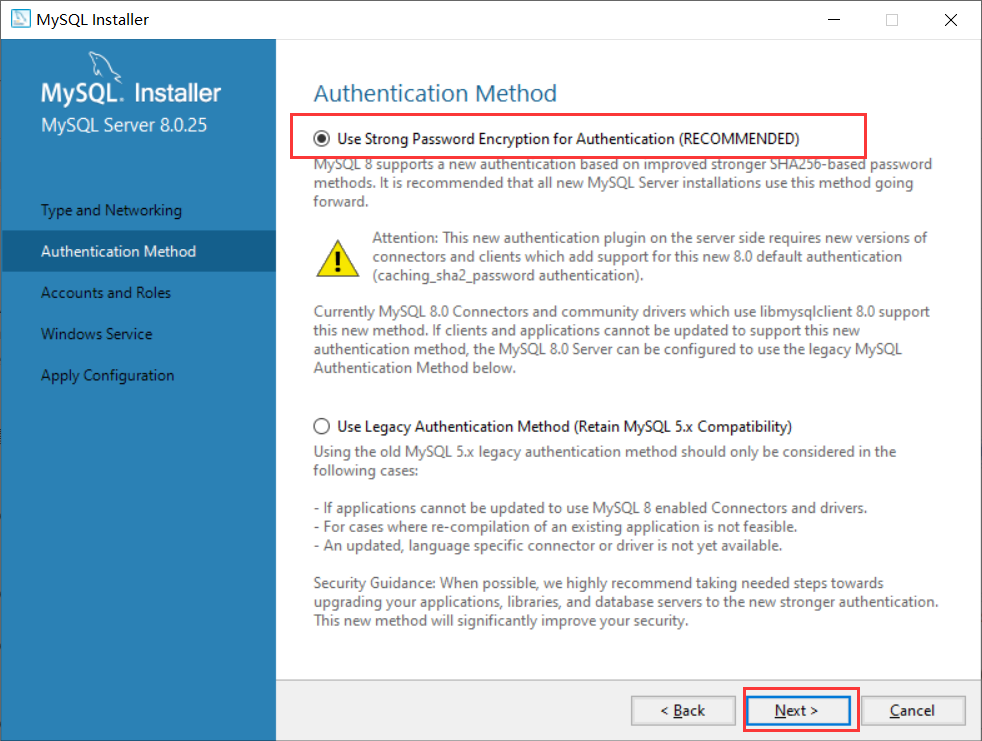
- 设置密码,两次密码输入保持一致,以后登录
MySQL就要用这个密码了,所以要记住: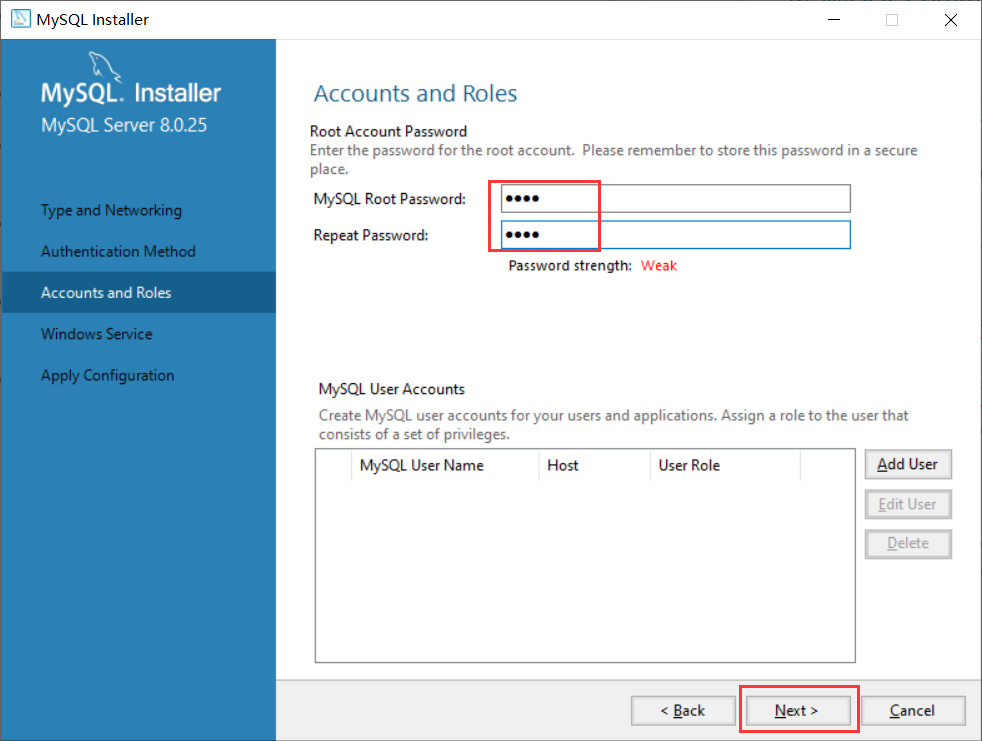
- 保持默认值,点击Next:
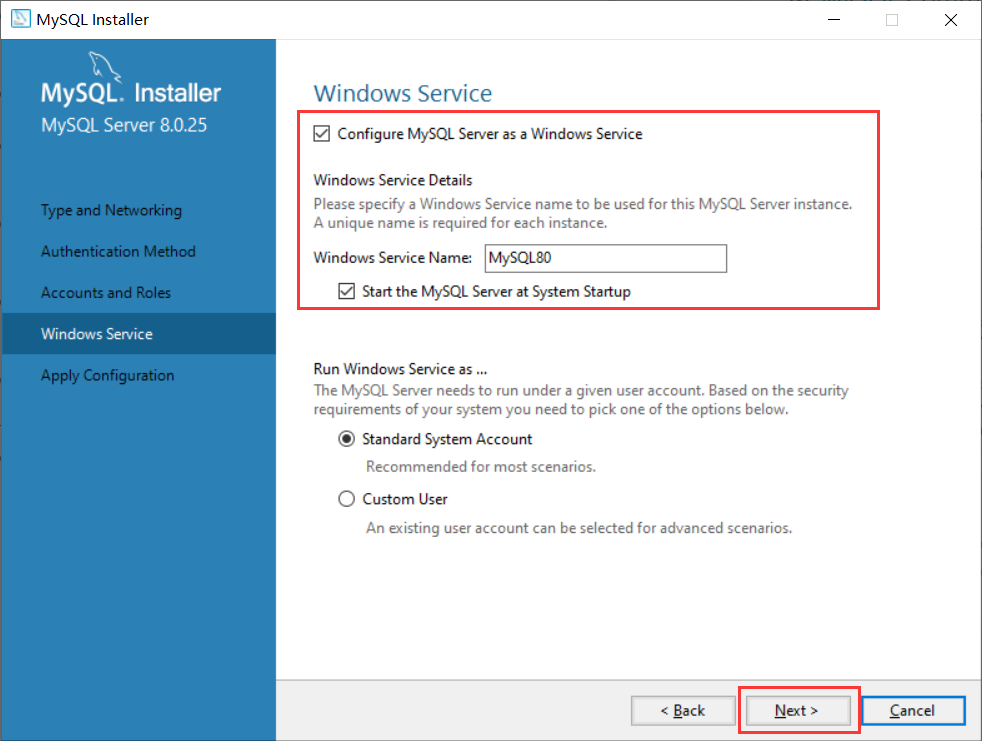
- 点击Next:
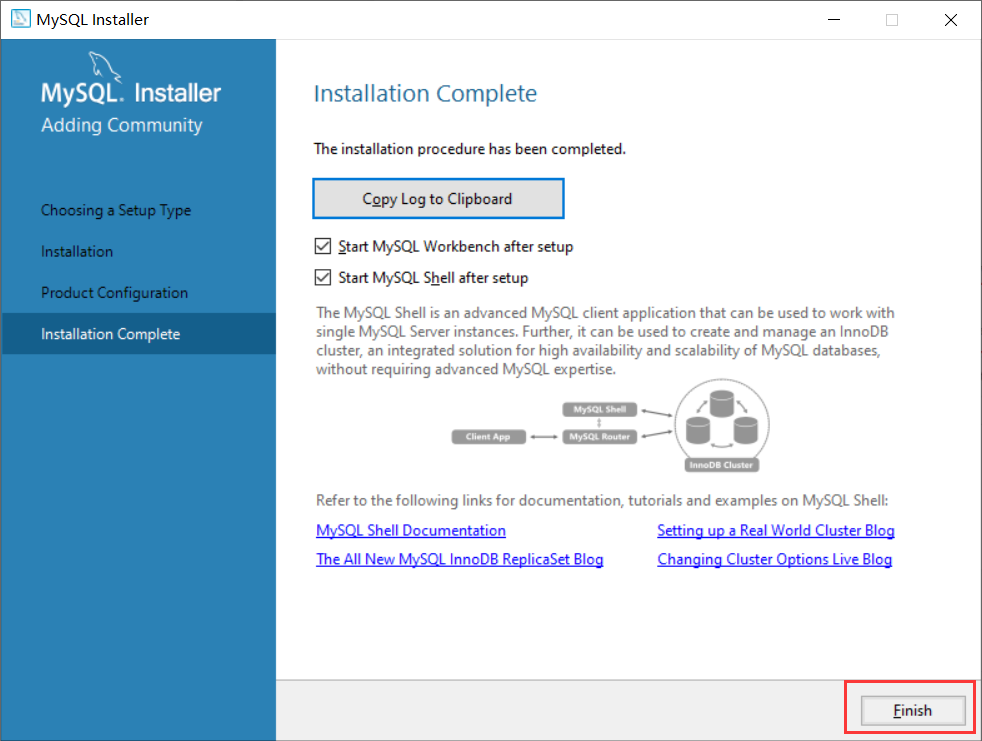
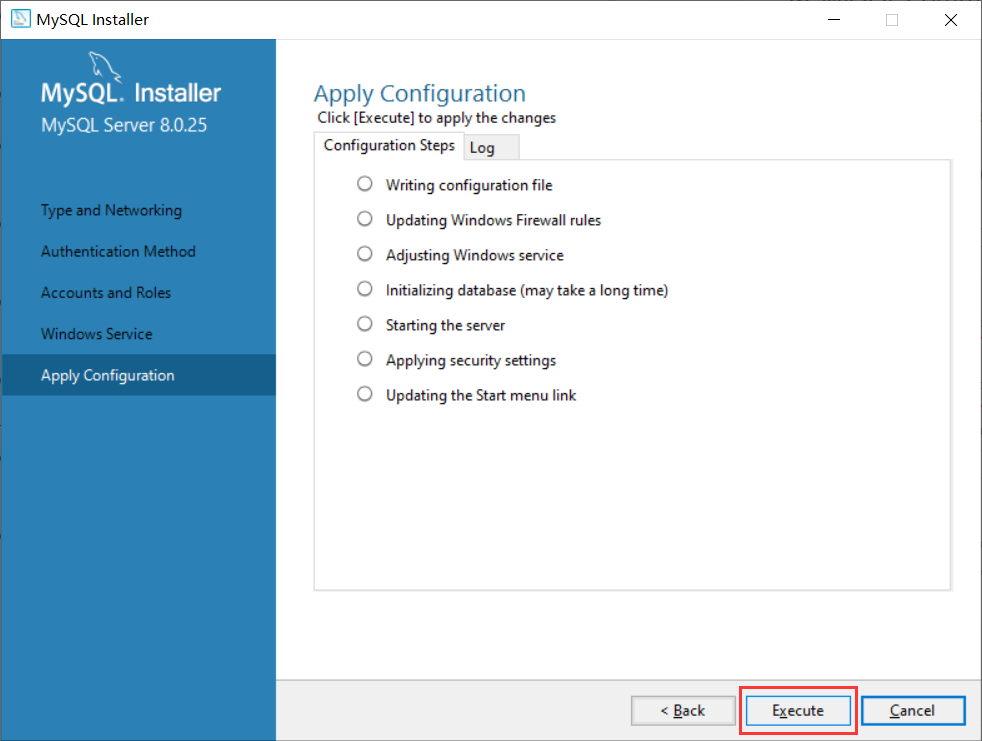 执行完后点击Finish
执行完后点击Finish
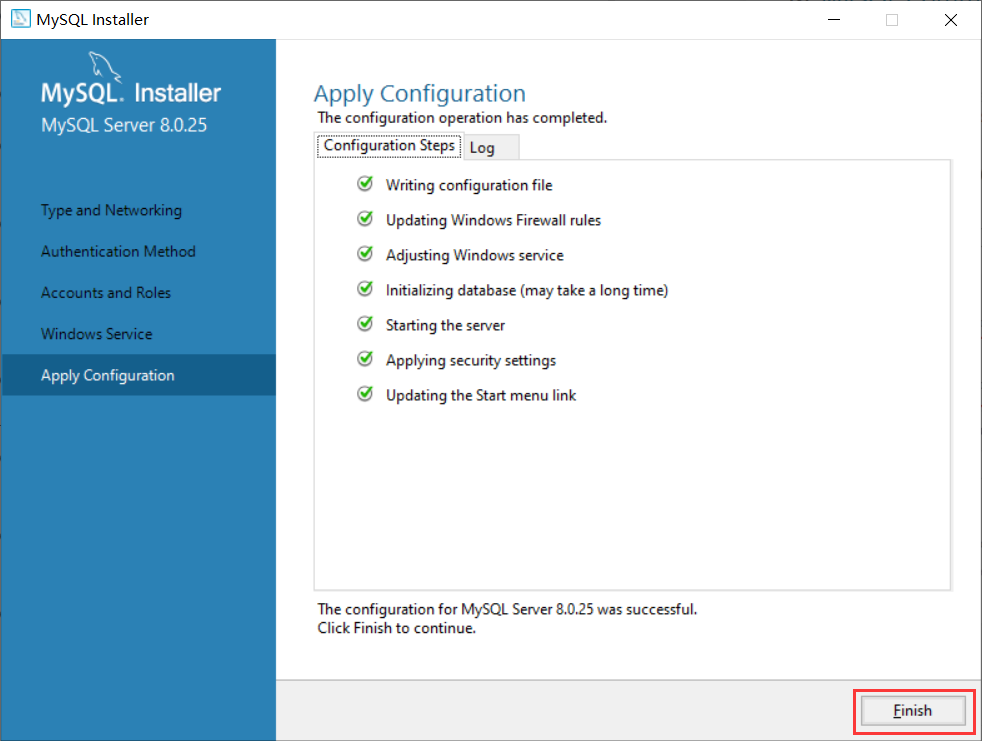
- 重新点击Next:
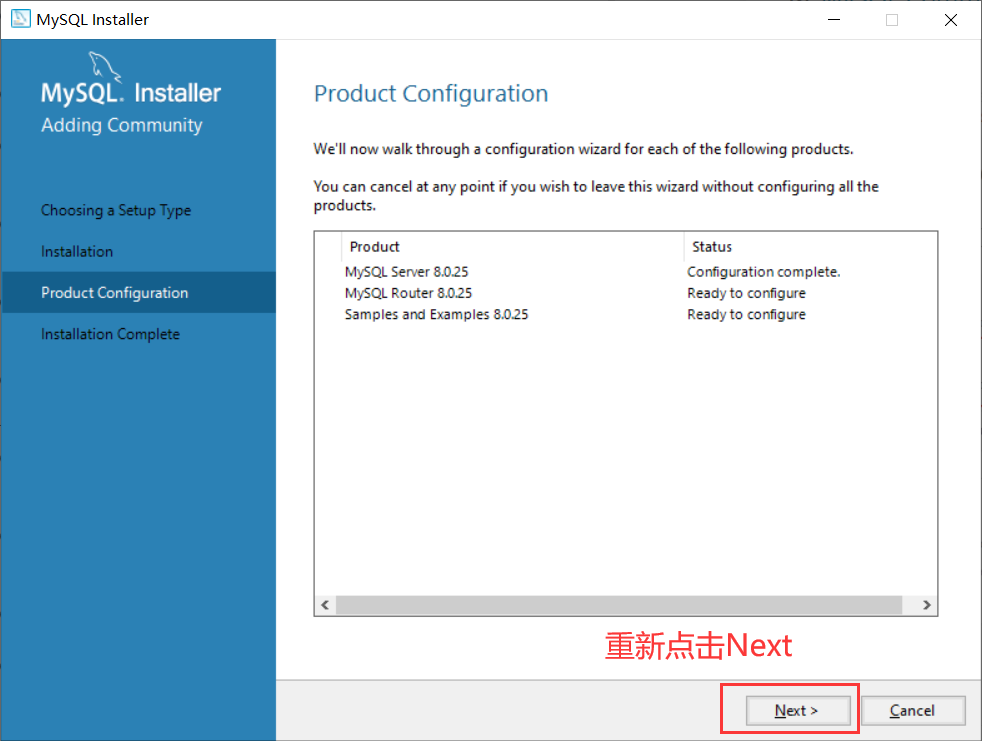
- 点击Next:
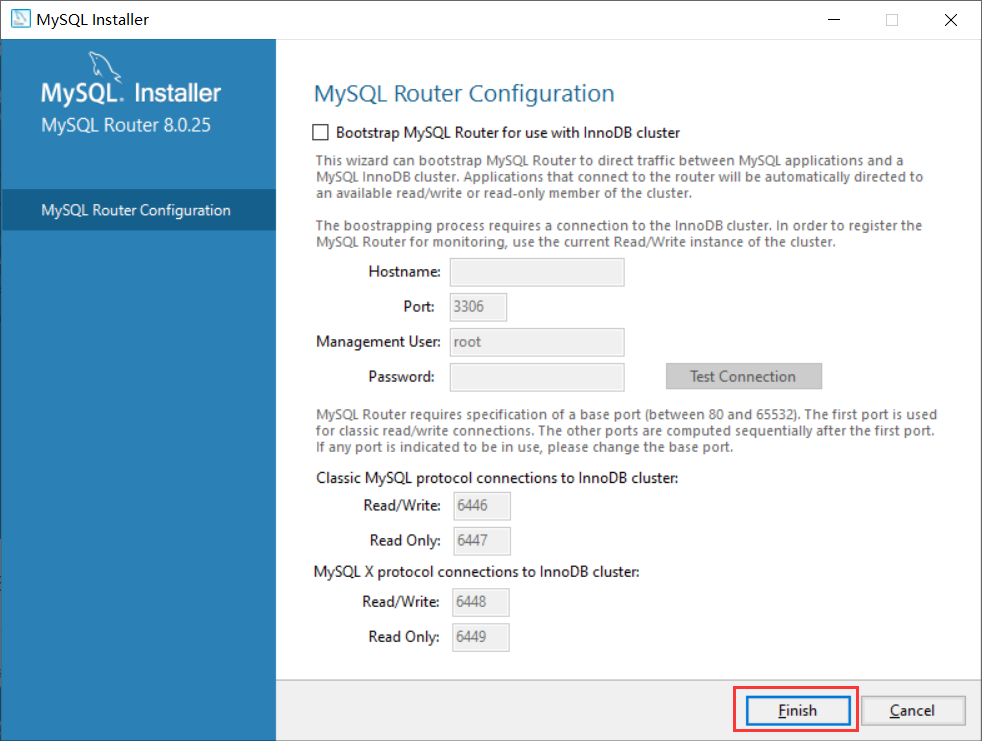
- 输入密码,点击Check:
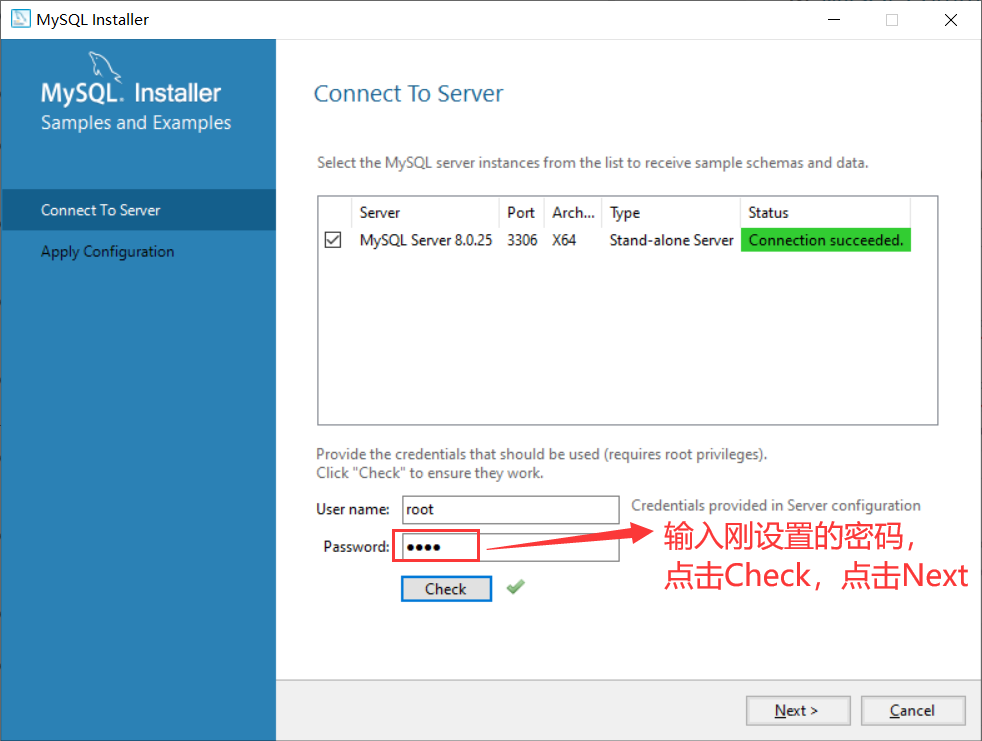
- 点击Finish,完成安装: