# 磁盘阵列
磁盘阵列(RAID,**R**edundant **A**rray of **I**ndependent **D**isks)是一种将多个物理硬盘组合在一起形成一个逻辑硬盘组的技术。通过 RAID,可以实现数据冗余、性能提升或两者兼具。RAID 在存储系统中广泛使用,尤其是在服务器和大数据存储环境中,用于提升数据可靠性和性能。
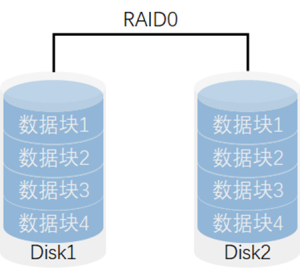
## **RAID 0(条带化,Striping)**
- **特点**: 将数据分块并在多个磁盘上并行存储,提升读写性能。
- **优点**: 极大提高了读写速度,因为数据在多个磁盘上并行操作。
- **缺点**: 没有冗余,任何一个磁盘的损坏都会导致整个 RAID 失效,数据丢失。
- **适用场景**: 需要高性能、数据安全性需求不高的场景,比如视频编辑、临时数据存储等。
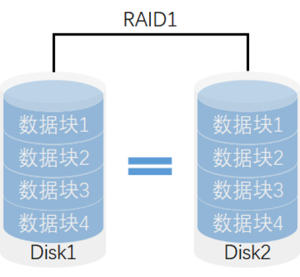
## **RAID 1(镜像,Mirroring)**
- **特点**: 将数据完全复制到另一块磁盘上,提供 1:1 的数据冗余。
- **优点**: 数据安全性高,任何一个磁盘损坏时,数据仍可以从镜像磁盘中恢复。
- **缺点**: 存储效率较低,实际可用存储空间为所有磁盘容量的一半。
- **适用场景**: 需要高数据可靠性和快速恢复的场合,比如数据库、操作系统磁盘等。
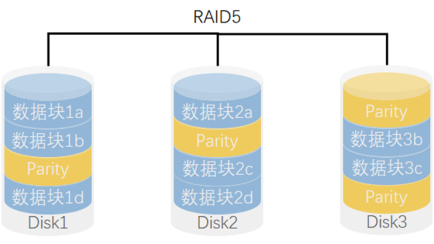
## **RAID 5(带奇偶校验的条带化,Striping with Parity)**
- **特点**: 将数据和奇偶校验数据分布在所有磁盘上,提供冗余的同时提升性能。
- **优点**: 提供数据冗余,同时存储效率较高(磁盘数量越多,效率越好),能够在一个磁盘损坏的情况下恢复数据。
- **缺点**: 写入性能稍差,尤其是在发生设备故障时,重建过程较慢。
- **适用场景**: 需要兼顾性能和数据冗余的场景,如文件服务器和应用服务器。
- 写性能*1,读性能\*(N-1)
RAID5的核心思想是使用奇偶校验信息来提供数据的冗余备份。当其中一个硬盘驱动器发生故障时,剩余的硬盘驱动器可以通过计算奇偶校验信息来恢复丢失的数据。这种方式既提供了数据冗余和容错能力,又降低了整体存储成本。
## **RAID 10(RAID 1+0,镜像与条带化的组合)**
- **特点**: 将 RAID 1(镜像)和 RAID 0(条带化)结合使用,既提供数据冗余又提升了性能。
- **优点**: 既有 RAID 0 的高性能,又有 RAID 1 的高安全性。能够快速恢复数据。
- **缺点**: 存储效率较低,要求至少 4 块磁盘,实际可用空间为所有磁盘容量的一半。
- **适用场景**: 需要高性能和高冗余的关键应用场景,如数据库、虚拟化环境等。
- 读写性能*N(N为RAID0的硬盘数,此例为2),不能同时坏数据块1a与2a
 ## **硬件磁盘阵列(Hardware RAID)**
### **特点**
- **专用硬件控制器**:硬件 RAID 使用专门的 RAID 控制器卡(RAID Controller),通常是插入主板的 PCIe 扩展卡或者集成在服务器主板上的芯片。该控制器管理磁盘阵列的所有操作并执行 RAID 级别的计算。
- **独立于操作系统**:硬件 RAID 完全独立于操作系统,RAID 控制器负责所有 RAID 相关操作,操作系统只看到一个逻辑磁盘。
- **硬件加速**:硬件 RAID 卡通常带有专用处理器(ASIC 或 FPGA)和缓存,用来加速 RAID 操作,提高性能
### 阵列卡
## **硬件磁盘阵列(Hardware RAID)**
### **特点**
- **专用硬件控制器**:硬件 RAID 使用专门的 RAID 控制器卡(RAID Controller),通常是插入主板的 PCIe 扩展卡或者集成在服务器主板上的芯片。该控制器管理磁盘阵列的所有操作并执行 RAID 级别的计算。
- **独立于操作系统**:硬件 RAID 完全独立于操作系统,RAID 控制器负责所有 RAID 相关操作,操作系统只看到一个逻辑磁盘。
- **硬件加速**:硬件 RAID 卡通常带有专用处理器(ASIC 或 FPGA)和缓存,用来加速 RAID 操作,提高性能
### 阵列卡
 ## **软件磁盘阵列(Software RAID)**
### **特点**
- **由操作系统实现**:软件 RAID 通过操作系统内核或专门的 RAID 软件来管理和实现 RAID 功能。Linux 的 `mdadm`、Windows 的动态磁盘管理和 macOS 的磁盘工具等都支持软件 RAID。
- **没有专用硬件**:软件 RAID 不需要专用的 RAID 控制器,所有 RAID 计算和管理工作都由主机的 CPU 执行。
- **灵活性高**:软件 RAID 通常可以在不同的硬件平台之间迁移,因为 RAID 配置数据存储在磁盘上,而不是特定的控制器中。
## **硬件 RAID 和软件 RAID 的对比**
| **对比项** | **硬件 RAID** | **软件 RAID** |
| ------------ | ---------------------------------------- | ---------------------------------- |
| **实现方式** | 专用 RAID 控制器 | 操作系统或软件实现 |
| **性能** | 高,特别是在 RAID 5/6 等级别中 | 较低,占用主机 CPU 资源 |
| **磁盘管理** | 独立于操作系统,系统只看到一个逻辑磁盘 | 依赖于操作系统的磁盘管理 |
| **成本** | 高,需购买 RAID 控制器 | 低,无需额外硬件 |
| **功能支持** | 支持热备盘、硬盘监控、电池缓存等高级功能 | 功能较少,依赖操作系统提供的功能 |
| **灵活性** | 依赖特定硬件,不易迁移 | 容易迁移,跨硬件平台使用 |
| **故障恢复** | 控制器损坏可能需要相同型号的控制器 | 可以在不同硬件上恢复 |
| **适用场景** | 企业级、大型存储系统,数据中心 | 个人用户、小型服务器,开发测试环境 |
# 部署磁盘阵列
为了后续实验,我们先添加5块全新的磁盘。关机状态下,在虚拟机设置中新增磁盘即可。最好添加完成以后,拍个快照保存一下。方便我们后续多次实验恢复。
## **软件磁盘阵列(Software RAID)**
### **特点**
- **由操作系统实现**:软件 RAID 通过操作系统内核或专门的 RAID 软件来管理和实现 RAID 功能。Linux 的 `mdadm`、Windows 的动态磁盘管理和 macOS 的磁盘工具等都支持软件 RAID。
- **没有专用硬件**:软件 RAID 不需要专用的 RAID 控制器,所有 RAID 计算和管理工作都由主机的 CPU 执行。
- **灵活性高**:软件 RAID 通常可以在不同的硬件平台之间迁移,因为 RAID 配置数据存储在磁盘上,而不是特定的控制器中。
## **硬件 RAID 和软件 RAID 的对比**
| **对比项** | **硬件 RAID** | **软件 RAID** |
| ------------ | ---------------------------------------- | ---------------------------------- |
| **实现方式** | 专用 RAID 控制器 | 操作系统或软件实现 |
| **性能** | 高,特别是在 RAID 5/6 等级别中 | 较低,占用主机 CPU 资源 |
| **磁盘管理** | 独立于操作系统,系统只看到一个逻辑磁盘 | 依赖于操作系统的磁盘管理 |
| **成本** | 高,需购买 RAID 控制器 | 低,无需额外硬件 |
| **功能支持** | 支持热备盘、硬盘监控、电池缓存等高级功能 | 功能较少,依赖操作系统提供的功能 |
| **灵活性** | 依赖特定硬件,不易迁移 | 容易迁移,跨硬件平台使用 |
| **故障恢复** | 控制器损坏可能需要相同型号的控制器 | 可以在不同硬件上恢复 |
| **适用场景** | 企业级、大型存储系统,数据中心 | 个人用户、小型服务器,开发测试环境 |
# 部署磁盘阵列
为了后续实验,我们先添加5块全新的磁盘。关机状态下,在虚拟机设置中新增磁盘即可。最好添加完成以后,拍个快照保存一下。方便我们后续多次实验恢复。
 ## mdadm磁盘整列
对于Linux上通过软件的形式构建磁盘整列,我们常用的方式是通过mdadm这个工具来完成。当然对于部分Linux发行版本,mdadm可能没有内置安装好,所以我们需要手动安装一下。
## 安装mdadm工具
yum是Linux中用于安装软件的工具,可以理解为应用商店
```sh
[root@localhost ~]# yum -y install mdadm
```
## mdadm命令
常用参数以及作用
| 参数 | 作用 |
| ---- | ---------------- |
| -a | 检测设备名称 |
| -n | 指定设备数量 |
| -l | 指定RAID级别 |
| -C | 创建 |
| -v | 显示过程 |
| -f | 模拟设备损坏 |
| -r | 移除设备 |
| -Q | 查看摘要信息 |
| -D | 查看详细信息 |
| -S | 停止RAID磁盘阵列 |
| -x | 备份盘数量 |
## RAID 0阵列实验
### 部署
1. 创建RAID 0阵列
```sh
[root@localhost ~]# mdadm -Cv /dev/md0 -a yes -n 2 -l 0 /dev/nvme0n2 /dev/nvme0n3
mdadm: chunk size defaults to 512K
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
[root@localhost ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sr0 11:0 1 1.7G 0 rom
nvme0n1 259:0 0 20G 0 disk
├─nvme0n1p1 259:1 0 1G 0 part /boot
└─nvme0n1p2 259:2 0 19G 0 part
├─rl-root 253:0 0 17G 0 lvm /
└─rl-swap 253:1 0 2G 0 lvm [SWAP]
nvme0n2 259:3 0 5G 0 disk
└─md0 9:0 0 10G 0 raid0
nvme0n3 259:4 0 5G 0 disk
└─md0 9:0 0 10G 0 raid0
nvme0n4 259:5 0 5G 0 disk
nvme0n5 259:6 0 5G 0 disk
nvme0n6 259:7 0 5G 0 disk
```
通过lsblk命令检查RAID 0阵列创建情况
2. 格式化文件系统
```sh
[root@localhost ~]# mkfs.ext4 /dev/md0
mke2fs 1.46.5 (30-Dec-2021)
/dev/md0 contains a ext4 file system
last mounted on Wed Nov 13 15:48:49 2024
Proceed anyway? (y,N) y
Creating filesystem with 2618880 4k blocks and 655360 inodes
Filesystem UUID: 8d1dcad6-2788-40db-8dbd-55b5b7105dbc
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
```
3. 创建挂载点,并对设备进行挂载
```sh
[root@localhost ~]# mkdir /mnt/RAID0
[root@localhost ~]# mount /dev/md0 /mnt/RAID0
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 872M 0 872M 0% /dev/shm
tmpfs 349M 6.3M 343M 2% /run
/dev/mapper/rl-root 17G 1.7G 16G 10% /
/dev/nvme0n1p1 960M 261M 700M 28% /boot
tmpfs 175M 0 175M 0% /run/user/0
/dev/md0 9.8G 24K 9.3G 1% /mnt/RAID0
# mount为临时挂载,也可以将挂载信息写入/etc/fstab文件中,进行永久挂载
[root@localhost ~]# echo "/dev/md0 /mnt/RAID0 ext4 defaults 0 0" >> /etc/fstab
[root@localhost ~]# mount -a
mount: (hint) your fstab has been modified, but systemd still uses
the old version; use 'systemctl daemon-reload' to reload.
[root@localhost ~]# systemctl daemon-reload
[root@localhost ~]# mount -a
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 872M 0 872M 0% /dev/shm
tmpfs 349M 6.3M 343M 2% /run
/dev/mapper/rl-root 17G 1.7G 16G 10% /
/dev/nvme0n1p1 960M 261M 700M 28% /boot
tmpfs 175M 0 175M 0% /run/user/0
/dev/md0 9.8G 24K 9.3G 1% /mnt/RAID0
# 确保fstab文件中的内容格式正确
```
4. 查看/dev/md0磁盘阵列的详细信息
```sh
[root@localhost ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Nov 14 16:10:58 2024
Raid Level : raid0
Array Size : 10475520 (9.99 GiB 10.73 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Thu Nov 14 16:10:58 2024
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Layout : original
Chunk Size : 512K
Consistency Policy : none
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 25a30480:323ceeda:d3d95a78:0f5321f7
Events : 0
Number Major Minor RaidDevice State
0 259 3 0 active sync /dev/nvme0n2
1 259 4 1 active sync /dev/nvme0n3
```
**部分字段解释:**
**Number**: 这个字段表示每个磁盘在 RAID 阵列中的编号(从 0 开始)。这是 RAID 阵列中每个设备的索引或设备号。
**Major**: 这是设备文件的主设备号(major number),它用于标识设备的类型。不同的主设备号通常对应不同的驱动程序或设备类别。
**Minor**: 这是设备文件的次设备号(minor number),用于标识同一类型设备中的不同实例。主设备号和次设备号共同唯一标识系统中的一个设备。
**RaidDevice**: 这是设备在 RAID 阵列中的逻辑设备编号。通常从 0 开始,表示该设备在 RAID 阵列中的顺序。
**State**: 表示 RAID 阵列中该设备的当前状态。常见状态如下:
- **active sync**: 表示该设备处于活动状态,并且与 RAID 阵列中的其他设备同步。
- **faulty**: 表示设备出现故障,不能正常工作。
- **spare**: 表示该设备是热备盘,当其他设备故障时可自动替换。
**set-A / set-B**: 这可能是与 RAID 10 或其他多组 RAID 配置相关的信息,表示该磁盘属于某个 RAID 子组或镜像组。例如,**set-A** 和 **set-B** 可能表示 RAID 10 配置中的两个镜像组。
**/dev/nvme0nX**: 这是设备的名称,表示设备在系统中的路径。在这里,设备是 NVMe 协议的磁盘(例如,`/dev/nvme0n2`)。不同的数字后缀(例如 `n2`, `n3` 等)表示不同的 NVMe 设备。
### 测试
通过fio磁盘测试工具来测试我们的RAID 0阵列的读写情况
```sh
[root@localhost ~]# yum install -y fio
```
#### 单块硬盘测试
```sh
# 先挂载单块硬盘
[root@localhost ~]# mkdir /mnt/test
[root@localhost ~]# mkfs.ext4 /dev/nvme0n4
mke2fs 1.46.5 (30-Dec-2021)
Creating filesystem with 1310720 4k blocks and 327680 inodes
Filesystem UUID: 0694e52f-3816-4223-b51b-6600bf32bb21
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
[root@localhost ~]# mount /dev/nvme0n4 /mnt/test
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 872M 0 872M 0% /dev/shm
tmpfs 349M 6.3M 343M 2% /run
/dev/mapper/rl-root 17G 1.7G 16G 10% /
/dev/nvme0n1p1 960M 261M 700M 28% /boot
tmpfs 175M 0 175M 0% /run/user/0
/dev/md0 9.8G 24K 9.3G 1% /mnt/RAID0
/dev/nvme0n4 4.9G 24K 4.6G 1% /mnt/test
# 开始测试
[root@localhost test]# fio --name=write_test --filename=/mnt/test/testfile --size=1G --bs=1M --rw=write --direct=1 --numjobs=1
write_test: (g=0): rw=write, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, i oengine=psync, iodepth=1
fio-3.35
Starting 1 process
write_test: Laying out IO file (1 file / 1024MiB)
write_test: (groupid=0, jobs=1): err= 0: pid=29670: Thu Nov 14 16:51:32 2024
write: IOPS=1404, BW=1405MiB/s (1473MB/s)(1024MiB/729msec); 0 zone resets
clat (usec): min=570, max=2700, avg=694.62, stdev=136.39
lat (usec): min=588, max=2709, avg=710.02, stdev=136.41
clat percentiles (usec):
| 1.00th=[ 586], 5.00th=[ 594], 10.00th=[ 603], 20.00th=[ 619],
| 30.00th=[ 635], 40.00th=[ 652], 50.00th=[ 668], 60.00th=[ 693],
| 70.00th=[ 709], 80.00th=[ 742], 90.00th=[ 783], 95.00th=[ 848],
| 99.00th=[ 1057], 99.50th=[ 1450], 99.90th=[ 2409], 99.95th=[ 2704],
| 99.99th=[ 2704]
bw ( MiB/s): min= 1400, max= 1400, per=99.67%, avg=1400.00, stdev= 0.00, samples=1
iops : min= 1400, max= 1400, avg=1400.00, stdev= 0.00, samples=1
lat (usec) : 750=83.11%, 1000=15.53%
lat (msec) : 2=1.07%, 4=0.29%
cpu : usr=0.14%, sys=8.52%, ctx=1024, majf=0, minf=8
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,1024,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
WRITE: bw=1405MiB/s (1473MB/s), 1405MiB/s-1405MiB/s (1473MB/s-1473MB/s), io=1024MiB (1074MB), run=729-729msec
Disk stats (read/write):
nvme0n4: ios=0/1793, merge=0/6, ticks=0/1173, in_queue=1173, util=86.50%
```
#### RAID 0测试
```sh
[root@localhost RAID0]# fio --name=write_test --filename=/mnt/RAID0/testfile --size=1G --bs=1M --rw=write --d irect=1 --numjobs=1
write_test: (g=0): rw=write, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync , iodepth=1
fio-3.35
Starting 1 process
write_test: Laying out IO file (1 file / 1024MiB)
write_test: (groupid=0, jobs=1): err= 0: pid=29232: Thu Nov 14 16:40:26 2024
write: IOPS=1314, BW=1315MiB/s (1378MB/s)(1024MiB/779msec); 0 zone resets
clat (usec): min=513, max=3382, avg=737.41, stdev=259.09
lat (usec): min=527, max=3469, avg=759.04, stdev=265.36
clat percentiles (usec):
| 1.00th=[ 537], 5.00th=[ 570], 10.00th=[ 578], 20.00th=[ 611],
| 30.00th=[ 627], 40.00th=[ 660], 50.00th=[ 676], 60.00th=[ 709],
| 70.00th=[ 758], 80.00th=[ 824], 90.00th=[ 898], 95.00th=[ 963],
| 99.00th=[ 2147], 99.50th=[ 2540], 99.90th=[ 3294], 99.95th=[ 3392],
| 99.99th=[ 3392]
bw ( MiB/s): min= 1275, max= 1275, per=97.03%, avg=1275.45, stdev= 0.00, samples=1
iops : min= 1275, max= 1275, avg=1275.00, stdev= 0.00, samples=1
lat (usec) : 750=69.43%, 1000=26.86%
lat (msec) : 2=2.34%, 4=1.37%
cpu : usr=0.39%, sys=9.77%, ctx=1024, majf=0, minf=10
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,1024,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
WRITE: bw=1315MiB/s (1378MB/s), 1315MiB/s-1315MiB/s (1378MB/s-1378MB/s), io=1024MiB (1074MB), run=779-779ms ec
Disk stats (read/write):
md0: ios=0/1660, merge=0/0, ticks=0/1229, in_queue=1229, util=86.06%, aggrios=0/1024, aggrmerge=0/0, aggr ticks=0/703, aggrin_queue=703, aggrutil=86.57%
nvme0n2: ios=0/1024, merge=0/0, ticks=0/702, in_queue=702, util=86.57%
nvme0n3: ios=0/1024, merge=0/0, ticks=0/705, in_queue=705, util=86.57%
```
由此可以看出,似乎单块磁盘和RAID 0的写入速度是差不多一样的。按道理来说,RAID 0是将数据分散在两块磁盘上,写入速度理应翻倍。但是由于这是虚拟机,使用我们自己电脑的物理磁盘,我们的物理硬盘只有一块,所以这里看不到RAID 0的双倍读写速度的效果。
### 删除磁盘阵列
```sh
# 先取消挂载,如果写入到fstab文件中,要记得删除
[root@localhost ~]# umount /dev/md0
# 停止磁盘整列
[root@localhost ~]# mdadm -S /dev/md0
mdadm: stopped /dev/md0
# 删除阵列中的数据块信息
[root@localhost ~]# mdadm --zero-superblock /dev/nvme0n2 /dev/nvme0n3
# 检查磁盘情况
[root@localhost ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sr0 11:0 1 1.7G 0 rom
nvme0n1 259:0 0 20G 0 disk
├─nvme0n1p1 259:1 0 1G 0 part /boot
└─nvme0n1p2 259:2 0 19G 0 part
├─rl-root 253:0 0 17G 0 lvm /
└─rl-swap 253:1 0 2G 0 lvm [SWAP]
nvme0n2 259:3 0 5G 0 disk
nvme0n3 259:4 0 5G 0 disk
nvme0n4 259:5 0 5G 0 disk /mnt/test
nvme0n5 259:6 0 5G 0 disk
nvme0n6 259:7 0 5G 0 disk
```
## RAID 1阵列实验
### 部署
按照上面实验中的方式,创建RAID1阵列以及完成挂载
```bash
[root@localhost ~]# mdadm -Cv /dev/md0 -a yes -n 2 -l 1 /dev/nvme0n2 /dev/nvme0n3
mdadm: Note: this array has metadata at the start and
may not be suitable as a boot device. If you plan to
store '/boot' on this device please ensure that
your boot-loader understands md/v1.x metadata, or use
--metadata=0.90
mdadm: size set to 5237760K
Continue creating array? y
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
[root@localhost ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sr0 11:0 1 1.7G 0 rom
nvme0n1 259:0 0 20G 0 disk
├─nvme0n1p1 259:1 0 1G 0 part /boot
└─nvme0n1p2 259:2 0 19G 0 part
├─rl-root 253:0 0 17G 0 lvm /
└─rl-swap 253:1 0 2G 0 lvm [SWAP]
nvme0n2 259:3 0 5G 0 disk
└─md0 9:0 0 5G 0 raid1
nvme0n3 259:4 0 5G 0 disk
└─md0 9:0 0 5G 0 raid1
nvme0n4 259:5 0 5G 0 disk /mnt/test
nvme0n5 259:6 0 5G 0 disk
nvme0n6 259:7 0 5G 0 disk
[root@localhost ~]# mkfs.ext4 /dev/md0
mke2fs 1.46.5 (30-Dec-2021)
/dev/md0 contains a ext4 file system
last mounted on /mnt/RAID0 on Thu Nov 14 16:39:48 2024
Proceed anyway? (y,N) y
Creating filesystem with 1309440 4k blocks and 327680 inodes
Filesystem UUID: fa3601df-6ddb-4471-afcc-fbf501a8e891
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
[root@localhost ~]# mkdir /mnt/RAID1
[root@localhost ~]# mount /dev/md0 /mnt/RAID1
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 872M 0 872M 0% /dev/shm
tmpfs 349M 6.3M 343M 2% /run
/dev/mapper/rl-root 17G 1.7G 16G 10% /
/dev/nvme0n1p1 960M 261M 700M 28% /boot
tmpfs 175M 0 175M 0% /run/user/0
/dev/nvme0n4 4.9G 1.1G 3.6G 22% /mnt/test
/dev/md0 4.9G 24K 4.6G 1% /mnt/RAID1
```
**注意最后的磁盘大小,我们将使用两块大小为5G的磁盘创建RAID1阵列。但是发现最后的磁盘大小还是5G,这也验证了RAID 1的特性,两块磁盘存放一样的数据,将数据镜像化,所以可用空间也会打对折**
### 磁盘写入测试
```sh
[root@localhost ~]# fio --name=write_test --filename=/mnt/RAID1/testfile --size=1G --bs=1M --rw=write --direct=1 --numjobs=1
write_test: (g=0): rw=write, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1
fio-3.35
Starting 1 process
write_test: Laying out IO file (1 file / 1024MiB)
Jobs: 1 (f=1)
write_test: (groupid=0, jobs=1): err= 0: pid=29656: Thu Nov 14 16:48:10 2024
write: IOPS=726, BW=727MiB/s (762MB/s)(1024MiB/1409msec); 0 zone resets
clat (usec): min=1057, max=6693, avg=1349.52, stdev=401.77
lat (usec): min=1074, max=6748, avg=1372.68, stdev=404.55
clat percentiles (usec):
| 1.00th=[ 1090], 5.00th=[ 1156], 10.00th=[ 1172], 20.00th=[ 1205],
| 30.00th=[ 1221], 40.00th=[ 1237], 50.00th=[ 1270], 60.00th=[ 1303],
| 70.00th=[ 1336], 80.00th=[ 1385], 90.00th=[ 1500], 95.00th=[ 1713],
| 99.00th=[ 3097], 99.50th=[ 3884], 99.90th=[ 5866], 99.95th=[ 6718],
| 99.99th=[ 6718]
bw ( KiB/s): min=716800, max=763904, per=99.48%, avg=740352.00, stdev=33307.56, samples=2
iops : min= 700, max= 746, avg=723.00, stdev=32.53, samples=2
lat (msec) : 2=96.58%, 4=2.93%, 10=0.49%
cpu : usr=0.36%, sys=7.53%, ctx=1031, majf=0, minf=9
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,1024,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
WRITE: bw=727MiB/s (762MB/s), 727MiB/s-727MiB/s (762MB/s-762MB/s), io=1024MiB (1074MB), run=1409-1409msec
Disk stats (read/write):
md0: ios=0/2009, merge=0/0, ticks=0/2531, in_queue=2531, util=92.94%, aggrios=0/2050, aggrmerge=0/0, aggrticks=0/2499, aggrin_queue=2500, aggrutil=91.91%
nvme0n2: ios=0/2050, merge=0/0, ticks=0/2476, in_queue=2477, util=91.91%
nvme0n3: ios=0/2050, merge=0/0, ticks=0/2522, in_queue=2523, util=91.91%
```
从测试结果中可以看见,RAID 1阵列的磁盘写入速度会比单块磁盘相对慢一点,因为RAID 1阵列是将一份数据写入两遍。
## RAID 10阵列实验
建议恢复快照到磁盘刚添加磁盘的状态。最少需要4块额外的硬盘
### 部署
1. 创建RAID 10阵列
```sh
[root@localhost ~]# mdadm -Cv /dev/md0 -a yes -n 4 -l 10 /dev/nvme0n2 /dev/nvme0n3 /dev/nvme0n4 /dev/nvme0n5
mdadm: layout defaults to n2
mdadm: layout defaults to n2
mdadm: chunk size defaults to 512K
mdadm: size set to 5237760K
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
[root@localhost ~]# mkfs.ext4 /dev/md0
mke2fs 1.46.5 (30-Dec-2021)
Creating filesystem with 2618880 4k blocks and 655360 inodes
Filesystem UUID: bd12aabd-52c7-41c3-81b8-bfb89a8ee580
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
[root@localhost ~]# mkdir /mnt/RAID10
[root@localhost ~]# mount /dev/md0 /mnt/RAID10
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 872M 0 872M 0% /dev/shm
tmpfs 349M 6.3M 343M 2% /run
/dev/mapper/rl-root 17G 1.7G 16G 10% /
/dev/nvme0n1p1 960M 261M 700M 28% /boot
tmpfs 175M 0 175M 0% /run/user/0
/dev/md0 9.8G 24K 9.3G 1% /mnt/RAID10
# 这里可以看到,虽然我们使用了4块大小为5G的硬盘,但是最后的实际大小只有10G。
```
2. 检查整列情况
```sh
[root@localhost ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Nov 14 17:07:34 2024
Raid Level : raid10
Array Size : 10475520 (9.99 GiB 10.73 GB)
Used Dev Size : 5237760 (5.00 GiB 5.36 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Nov 14 17:21:26 2024
State : clean
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 7011a5e6:862c3556:6bbba92b:8a61ce4e
Events : 17
Number Major Minor RaidDevice State
0 259 3 0 active sync set-A /dev/nvme0n2
1 259 4 1 active sync set-B /dev/nvme0n3
2 259 5 2 active sync set-A /dev/nvme0n4
3 259 6 3 active sync set-B /dev/nvme0n5
```
### 磁盘写入测试
```sh
[root@localhost RAID10]# fio --name=write_test --filename=/mnt/RAID10/testfile --size=1G --bs=1M --rw=write --direct=1 --numjobs=1
write_test: (g=0): rw=write, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1
fio-3.35
Starting 1 process
write_test: Laying out IO file (1 file / 1024MiB)
Jobs: 1 (f=1)
write_test: (groupid=0, jobs=1): err= 0: pid=27150: Thu Nov 14 17:29:34 2024
write: IOPS=715, BW=715MiB/s (750MB/s)(1024MiB/1432msec); 0 zone resets
clat (usec): min=1122, max=5646, avg=1373.87, stdev=264.26
lat (usec): min=1140, max=5741, avg=1395.28, stdev=266.74
clat percentiles (usec):
| 1.00th=[ 1156], 5.00th=[ 1205], 10.00th=[ 1221], 20.00th=[ 1254],
| 30.00th=[ 1287], 40.00th=[ 1303], 50.00th=[ 1336], 60.00th=[ 1369],
| 70.00th=[ 1401], 80.00th=[ 1450], 90.00th=[ 1516], 95.00th=[ 1614],
| 99.00th=[ 2040], 99.50th=[ 2606], 99.90th=[ 5669], 99.95th=[ 5669],
| 99.99th=[ 5669]
bw ( KiB/s): min=733184, max=737852, per=100.00%, avg=735518.00, stdev=3300.77, samples=2
iops : min= 716, max= 720, avg=718.00, stdev= 2.83, samples=2
lat (msec) : 2=98.73%, 4=1.07%, 10=0.20%
cpu : usr=0.49%, sys=6.57%, ctx=1026, majf=0, minf=10
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,1024,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
WRITE: bw=715MiB/s (750MB/s), 715MiB/s-715MiB/s (750MB/s-750MB/s), io=1024MiB (1074MB), run=1432-1432msec
Disk stats (read/write):
md0: ios=0/1984, merge=0/0, ticks=0/2554, in_queue=2554, util=93.47%, aggrios=0/1024, aggrmerge=0/0, aggrticks=0/1284, aggrin_queue=1284, aggrutil=92.57%
nvme0n4: ios=0/1024, merge=0/0, ticks=0/1272, in_queue=1272, util=92.31%
nvme0n2: ios=0/1024, merge=0/0, ticks=0/1277, in_queue=1278, util=92.31%
nvme0n5: ios=0/1024, merge=0/0, ticks=0/1312, in_queue=1312, util=92.57%
nvme0n3: ios=0/1024, merge=0/0, ticks=0/1277, in_queue=1277, util=92.31%
```
### 损坏磁盘阵列及修复
在确认有一块物理硬盘设备出现损坏而不能继续正常使用后,应该使用mdadm命令将其移除,然后查看RAID磁盘阵列的状态,可以发现状态已经改变。
```bash
[root@localhost RAID10]# mdadm /dev/md0 -f /dev/nvme0n2
mdadm: set /dev/nvme0n2 faulty in /dev/md0
[root@localhost RAID10]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Nov 14 17:07:34 2024
Raid Level : raid10
Array Size : 10475520 (9.99 GiB 10.73 GB)
Used Dev Size : 5237760 (5.00 GiB 5.36 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Fri Nov 15 10:05:55 2024
State : clean, degraded
Active Devices : 3
Working Devices : 3
Failed Devices : 1
Spare Devices : 0
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 7011a5e6:862c3556:6bbba92b:8a61ce4e
Events : 19
Number Major Minor RaidDevice State
- 0 0 0 removed
1 259 4 1 active sync set-B /dev/nvme0n3
2 259 5 2 active sync set-A /dev/nvme0n4
3 259 6 3 active sync set-B /dev/nvme0n5
0 259 3 - faulty /dev/nvme0n2
```
在RAID 10级别的磁盘阵列中,当RAID 1磁盘阵列中存在一个故障盘时并不影响RAID 10磁盘阵列的使用。当购买了新的硬盘设备后再使用mdadm命令来予以替换即可,在此期间我们可以在/RAID目录中正常地创建或删除文件。由于我们是在虚拟机中模拟硬盘,所以先重启系统,然后再把新的硬盘添加到RAID磁盘阵列中。
```bash
[root@localhost ~]# umount /mnt/RAID10
#有时候失败,告诉设备忙,-f参数都没用
#可以使用fuser -mk /mnt/RAID10命令杀死所有占用该文件的进程
# 先热移除/dev/nvme0n2
[root@localhost ~]# mdadm /dev/md0 -r /dev/nvme0n2
mdadm: hot removed /dev/nvme0n2 from /dev/md0
[root@localhost ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Nov 14 17:07:34 2024
Raid Level : raid10
Array Size : 10475520 (9.99 GiB 10.73 GB)
Used Dev Size : 5237760 (5.00 GiB 5.36 GB)
Raid Devices : 4
Total Devices : 3
Persistence : Superblock is persistent
Update Time : Fri Nov 15 10:09:16 2024
State : clean, degraded
Active Devices : 3
Working Devices : 3
Failed Devices : 0
Spare Devices : 0
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 7011a5e6:862c3556:6bbba92b:8a61ce4e
Events : 22
Number Major Minor RaidDevice State
- 0 0 0 removed
1 259 4 1 active sync set-B /dev/nvme0n3
2 259 5 2 active sync set-A /dev/nvme0n4
3 259 6 3 active sync set-B /dev/nvme0n5
# 再重新添加/dev/nvme0n2
[root@localhost ~]# mdadm /dev/md0 -a /dev/nvme0n2
mdadm: added /dev/nvme0n2
[root@localhost ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Nov 14 17:07:34 2024
Raid Level : raid10
Array Size : 10475520 (9.99 GiB 10.73 GB)
Used Dev Size : 5237760 (5.00 GiB 5.36 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Fri Nov 15 10:10:25 2024
State : clean, degraded, recovering
Active Devices : 3
Working Devices : 4
Failed Devices : 0
Spare Devices : 1
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Rebuild Status : 31% complete
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 7011a5e6:862c3556:6bbba92b:8a61ce4e
Events : 28
Number Major Minor RaidDevice State
4 259 3 0 spare rebuilding /dev/nvme0n2
1 259 4 1 active sync set-B /dev/nvme0n3
2 259 5 2 active sync set-A /dev/nvme0n4
3 259 6 3 active sync set-B /dev/nvme0n5
# 会发现,刚添加上的磁盘处于rebuilding的状态,等待一会儿,就会恢复正常了。
# 重新再次挂载即可正常使用
[root@localhost ~]# mount /dev/md0 /mnt/RAID10/
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 872M 0 872M 0% /dev/shm
tmpfs 349M 6.3M 343M 2% /run
/dev/mapper/rl-root 17G 1.7G 16G 10% /
/dev/nvme0n1p1 960M 261M 700M 28% /boot
tmpfs 175M 0 175M 0% /run/user/0
/dev/md0 9.8G 1.1G 8.3G 11% /mnt/RAID10
# 有的时候,可能会存在/dev/nvme0n2无法添加的情况,对于这种情况,只能将整个整列全部删除干净之后重新创建
```
## RAID 5阵列实验+备份盘
为了避免多个实验之间相互发生冲突,我们需要保证每个实验的相对独立性,为此需要大家自行将虚拟机还原到初始状态。
部署RAID 5磁盘阵列时,至少需要用到3块硬盘,还需要再加一块备份硬盘,所以总计需要在虚拟机中模拟4块硬盘设备
现在创建一个RAID 5磁盘阵列+备份盘。在下面的命令中,参数-n 3代表创建这个RAID 5磁盘阵列所需的硬盘数,参数-l 5代表RAID的级别,而参数-x 1则代表有一块备份盘。当查看/dev/md0(即RAID 5磁盘阵列的名称)磁盘阵列的时候就能看到有一块备份盘在等待中了。
```bash
[root@localhost ~]# mdadm -Cv /dev/md0 -n 3 -l 5 -x 1 /dev/nvme0n2 /dev/nvme0n3 /dev/nvme0n4 /dev/nvme0n5
mdadm: layout defaults to left-symmetric
mdadm: layout defaults to left-symmetric
mdadm: chunk size defaults to 512K
mdadm: size set to 5237760K
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
[root@localhost ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Fri Nov 15 10:33:07 2024
Raid Level : raid5
Array Size : 10475520 (9.99 GiB 10.73 GB)
Used Dev Size : 5237760 (5.00 GiB 5.36 GB)
Raid Devices : 3
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Fri Nov 15 10:33:33 2024
State : clean
Active Devices : 3
Working Devices : 4
Failed Devices : 0
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Consistency Policy : resync
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 8f9130a4:06668353:958e7628:985d1167
Events : 18
Number Major Minor RaidDevice State
0 259 3 0 active sync /dev/nvme0n2
1 259 4 1 active sync /dev/nvme0n3
4 259 5 2 active sync /dev/nvme0n4
3 259 6 - spare /dev/nvme0n5
```
将部署好的RAID 5磁盘阵列格式化为ext4文件格式,然后挂载到目录上,之后就可以使用了。
```bash
[root@localhost ~]# mkfs.ext4 /dev/md0
mke2fs 1.46.5 (30-Dec-2021)
Creating filesystem with 2618880 4k blocks and 655360 inodes
Filesystem UUID: 33c5ee4e-82de-4c0f-98f1-88cda85292ea
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
[root@localhost ~]# mkdir /mnt/RAID5
[root@localhost ~]# echo "/dev/md0 /mnt/RAID5 ext4 defaults 0 0" >> /etc/fstab
[root@localhost ~]# mount -a
mount: (hint) your fstab has been modified, but systemd still uses
the old version; use 'systemctl daemon-reload' to reload.
[root@localhost ~]# systemctl daemon-reload
[root@localhost ~]# mount -a
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 872M 0 872M 0% /dev/shm
tmpfs 349M 6.3M 343M 2% /run
/dev/mapper/rl-root 17G 1.7G 16G 10% /
/dev/nvme0n1p1 960M 261M 700M 28% /boot
tmpfs 175M 0 175M 0% /run/user/0
/dev/md0 9.8G 24K 9.3G 1% /mnt/RAID5
```
把硬盘设备/dev/nvme0n2移出磁盘阵列,然后迅速查看/dev/md0磁盘阵列的状态
```bash
[root@localhost ~]# mdadm /dev/md0 -f /dev/nvme0n2
mdadm: set /dev/nvme0n2 faulty in /dev/md0
# /dev/nvme0n5由原来的spare顶上来变成spare-building
[root@localhost ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Fri Nov 15 10:33:07 2024
Raid Level : raid5
Array Size : 10475520 (9.99 GiB 10.73 GB)
Used Dev Size : 5237760 (5.00 GiB 5.36 GB)
Raid Devices : 3
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Fri Nov 15 10:41:21 2024
State : clean, degraded, recovering
Active Devices : 2
Working Devices : 3
Failed Devices : 1
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Consistency Policy : resync
Rebuild Status : 11% complete
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 8f9130a4:06668353:958e7628:985d1167
Events : 21
Number Major Minor RaidDevice State
3 259 6 0 spare rebuilding /dev/nvme0n5
1 259 4 1 active sync /dev/nvme0n3
4 259 5 2 active sync /dev/nvme0n4
0 259 3 - faulty /dev/nvme0n2
# 然后过一会儿,/dev/nvme0n5的状态就会变成active sync
```
## mdadm磁盘整列
对于Linux上通过软件的形式构建磁盘整列,我们常用的方式是通过mdadm这个工具来完成。当然对于部分Linux发行版本,mdadm可能没有内置安装好,所以我们需要手动安装一下。
## 安装mdadm工具
yum是Linux中用于安装软件的工具,可以理解为应用商店
```sh
[root@localhost ~]# yum -y install mdadm
```
## mdadm命令
常用参数以及作用
| 参数 | 作用 |
| ---- | ---------------- |
| -a | 检测设备名称 |
| -n | 指定设备数量 |
| -l | 指定RAID级别 |
| -C | 创建 |
| -v | 显示过程 |
| -f | 模拟设备损坏 |
| -r | 移除设备 |
| -Q | 查看摘要信息 |
| -D | 查看详细信息 |
| -S | 停止RAID磁盘阵列 |
| -x | 备份盘数量 |
## RAID 0阵列实验
### 部署
1. 创建RAID 0阵列
```sh
[root@localhost ~]# mdadm -Cv /dev/md0 -a yes -n 2 -l 0 /dev/nvme0n2 /dev/nvme0n3
mdadm: chunk size defaults to 512K
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
[root@localhost ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sr0 11:0 1 1.7G 0 rom
nvme0n1 259:0 0 20G 0 disk
├─nvme0n1p1 259:1 0 1G 0 part /boot
└─nvme0n1p2 259:2 0 19G 0 part
├─rl-root 253:0 0 17G 0 lvm /
└─rl-swap 253:1 0 2G 0 lvm [SWAP]
nvme0n2 259:3 0 5G 0 disk
└─md0 9:0 0 10G 0 raid0
nvme0n3 259:4 0 5G 0 disk
└─md0 9:0 0 10G 0 raid0
nvme0n4 259:5 0 5G 0 disk
nvme0n5 259:6 0 5G 0 disk
nvme0n6 259:7 0 5G 0 disk
```
通过lsblk命令检查RAID 0阵列创建情况
2. 格式化文件系统
```sh
[root@localhost ~]# mkfs.ext4 /dev/md0
mke2fs 1.46.5 (30-Dec-2021)
/dev/md0 contains a ext4 file system
last mounted on Wed Nov 13 15:48:49 2024
Proceed anyway? (y,N) y
Creating filesystem with 2618880 4k blocks and 655360 inodes
Filesystem UUID: 8d1dcad6-2788-40db-8dbd-55b5b7105dbc
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
```
3. 创建挂载点,并对设备进行挂载
```sh
[root@localhost ~]# mkdir /mnt/RAID0
[root@localhost ~]# mount /dev/md0 /mnt/RAID0
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 872M 0 872M 0% /dev/shm
tmpfs 349M 6.3M 343M 2% /run
/dev/mapper/rl-root 17G 1.7G 16G 10% /
/dev/nvme0n1p1 960M 261M 700M 28% /boot
tmpfs 175M 0 175M 0% /run/user/0
/dev/md0 9.8G 24K 9.3G 1% /mnt/RAID0
# mount为临时挂载,也可以将挂载信息写入/etc/fstab文件中,进行永久挂载
[root@localhost ~]# echo "/dev/md0 /mnt/RAID0 ext4 defaults 0 0" >> /etc/fstab
[root@localhost ~]# mount -a
mount: (hint) your fstab has been modified, but systemd still uses
the old version; use 'systemctl daemon-reload' to reload.
[root@localhost ~]# systemctl daemon-reload
[root@localhost ~]# mount -a
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 872M 0 872M 0% /dev/shm
tmpfs 349M 6.3M 343M 2% /run
/dev/mapper/rl-root 17G 1.7G 16G 10% /
/dev/nvme0n1p1 960M 261M 700M 28% /boot
tmpfs 175M 0 175M 0% /run/user/0
/dev/md0 9.8G 24K 9.3G 1% /mnt/RAID0
# 确保fstab文件中的内容格式正确
```
4. 查看/dev/md0磁盘阵列的详细信息
```sh
[root@localhost ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Nov 14 16:10:58 2024
Raid Level : raid0
Array Size : 10475520 (9.99 GiB 10.73 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Thu Nov 14 16:10:58 2024
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Layout : original
Chunk Size : 512K
Consistency Policy : none
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 25a30480:323ceeda:d3d95a78:0f5321f7
Events : 0
Number Major Minor RaidDevice State
0 259 3 0 active sync /dev/nvme0n2
1 259 4 1 active sync /dev/nvme0n3
```
**部分字段解释:**
**Number**: 这个字段表示每个磁盘在 RAID 阵列中的编号(从 0 开始)。这是 RAID 阵列中每个设备的索引或设备号。
**Major**: 这是设备文件的主设备号(major number),它用于标识设备的类型。不同的主设备号通常对应不同的驱动程序或设备类别。
**Minor**: 这是设备文件的次设备号(minor number),用于标识同一类型设备中的不同实例。主设备号和次设备号共同唯一标识系统中的一个设备。
**RaidDevice**: 这是设备在 RAID 阵列中的逻辑设备编号。通常从 0 开始,表示该设备在 RAID 阵列中的顺序。
**State**: 表示 RAID 阵列中该设备的当前状态。常见状态如下:
- **active sync**: 表示该设备处于活动状态,并且与 RAID 阵列中的其他设备同步。
- **faulty**: 表示设备出现故障,不能正常工作。
- **spare**: 表示该设备是热备盘,当其他设备故障时可自动替换。
**set-A / set-B**: 这可能是与 RAID 10 或其他多组 RAID 配置相关的信息,表示该磁盘属于某个 RAID 子组或镜像组。例如,**set-A** 和 **set-B** 可能表示 RAID 10 配置中的两个镜像组。
**/dev/nvme0nX**: 这是设备的名称,表示设备在系统中的路径。在这里,设备是 NVMe 协议的磁盘(例如,`/dev/nvme0n2`)。不同的数字后缀(例如 `n2`, `n3` 等)表示不同的 NVMe 设备。
### 测试
通过fio磁盘测试工具来测试我们的RAID 0阵列的读写情况
```sh
[root@localhost ~]# yum install -y fio
```
#### 单块硬盘测试
```sh
# 先挂载单块硬盘
[root@localhost ~]# mkdir /mnt/test
[root@localhost ~]# mkfs.ext4 /dev/nvme0n4
mke2fs 1.46.5 (30-Dec-2021)
Creating filesystem with 1310720 4k blocks and 327680 inodes
Filesystem UUID: 0694e52f-3816-4223-b51b-6600bf32bb21
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
[root@localhost ~]# mount /dev/nvme0n4 /mnt/test
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 872M 0 872M 0% /dev/shm
tmpfs 349M 6.3M 343M 2% /run
/dev/mapper/rl-root 17G 1.7G 16G 10% /
/dev/nvme0n1p1 960M 261M 700M 28% /boot
tmpfs 175M 0 175M 0% /run/user/0
/dev/md0 9.8G 24K 9.3G 1% /mnt/RAID0
/dev/nvme0n4 4.9G 24K 4.6G 1% /mnt/test
# 开始测试
[root@localhost test]# fio --name=write_test --filename=/mnt/test/testfile --size=1G --bs=1M --rw=write --direct=1 --numjobs=1
write_test: (g=0): rw=write, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, i oengine=psync, iodepth=1
fio-3.35
Starting 1 process
write_test: Laying out IO file (1 file / 1024MiB)
write_test: (groupid=0, jobs=1): err= 0: pid=29670: Thu Nov 14 16:51:32 2024
write: IOPS=1404, BW=1405MiB/s (1473MB/s)(1024MiB/729msec); 0 zone resets
clat (usec): min=570, max=2700, avg=694.62, stdev=136.39
lat (usec): min=588, max=2709, avg=710.02, stdev=136.41
clat percentiles (usec):
| 1.00th=[ 586], 5.00th=[ 594], 10.00th=[ 603], 20.00th=[ 619],
| 30.00th=[ 635], 40.00th=[ 652], 50.00th=[ 668], 60.00th=[ 693],
| 70.00th=[ 709], 80.00th=[ 742], 90.00th=[ 783], 95.00th=[ 848],
| 99.00th=[ 1057], 99.50th=[ 1450], 99.90th=[ 2409], 99.95th=[ 2704],
| 99.99th=[ 2704]
bw ( MiB/s): min= 1400, max= 1400, per=99.67%, avg=1400.00, stdev= 0.00, samples=1
iops : min= 1400, max= 1400, avg=1400.00, stdev= 0.00, samples=1
lat (usec) : 750=83.11%, 1000=15.53%
lat (msec) : 2=1.07%, 4=0.29%
cpu : usr=0.14%, sys=8.52%, ctx=1024, majf=0, minf=8
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,1024,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
WRITE: bw=1405MiB/s (1473MB/s), 1405MiB/s-1405MiB/s (1473MB/s-1473MB/s), io=1024MiB (1074MB), run=729-729msec
Disk stats (read/write):
nvme0n4: ios=0/1793, merge=0/6, ticks=0/1173, in_queue=1173, util=86.50%
```
#### RAID 0测试
```sh
[root@localhost RAID0]# fio --name=write_test --filename=/mnt/RAID0/testfile --size=1G --bs=1M --rw=write --d irect=1 --numjobs=1
write_test: (g=0): rw=write, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync , iodepth=1
fio-3.35
Starting 1 process
write_test: Laying out IO file (1 file / 1024MiB)
write_test: (groupid=0, jobs=1): err= 0: pid=29232: Thu Nov 14 16:40:26 2024
write: IOPS=1314, BW=1315MiB/s (1378MB/s)(1024MiB/779msec); 0 zone resets
clat (usec): min=513, max=3382, avg=737.41, stdev=259.09
lat (usec): min=527, max=3469, avg=759.04, stdev=265.36
clat percentiles (usec):
| 1.00th=[ 537], 5.00th=[ 570], 10.00th=[ 578], 20.00th=[ 611],
| 30.00th=[ 627], 40.00th=[ 660], 50.00th=[ 676], 60.00th=[ 709],
| 70.00th=[ 758], 80.00th=[ 824], 90.00th=[ 898], 95.00th=[ 963],
| 99.00th=[ 2147], 99.50th=[ 2540], 99.90th=[ 3294], 99.95th=[ 3392],
| 99.99th=[ 3392]
bw ( MiB/s): min= 1275, max= 1275, per=97.03%, avg=1275.45, stdev= 0.00, samples=1
iops : min= 1275, max= 1275, avg=1275.00, stdev= 0.00, samples=1
lat (usec) : 750=69.43%, 1000=26.86%
lat (msec) : 2=2.34%, 4=1.37%
cpu : usr=0.39%, sys=9.77%, ctx=1024, majf=0, minf=10
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,1024,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
WRITE: bw=1315MiB/s (1378MB/s), 1315MiB/s-1315MiB/s (1378MB/s-1378MB/s), io=1024MiB (1074MB), run=779-779ms ec
Disk stats (read/write):
md0: ios=0/1660, merge=0/0, ticks=0/1229, in_queue=1229, util=86.06%, aggrios=0/1024, aggrmerge=0/0, aggr ticks=0/703, aggrin_queue=703, aggrutil=86.57%
nvme0n2: ios=0/1024, merge=0/0, ticks=0/702, in_queue=702, util=86.57%
nvme0n3: ios=0/1024, merge=0/0, ticks=0/705, in_queue=705, util=86.57%
```
由此可以看出,似乎单块磁盘和RAID 0的写入速度是差不多一样的。按道理来说,RAID 0是将数据分散在两块磁盘上,写入速度理应翻倍。但是由于这是虚拟机,使用我们自己电脑的物理磁盘,我们的物理硬盘只有一块,所以这里看不到RAID 0的双倍读写速度的效果。
### 删除磁盘阵列
```sh
# 先取消挂载,如果写入到fstab文件中,要记得删除
[root@localhost ~]# umount /dev/md0
# 停止磁盘整列
[root@localhost ~]# mdadm -S /dev/md0
mdadm: stopped /dev/md0
# 删除阵列中的数据块信息
[root@localhost ~]# mdadm --zero-superblock /dev/nvme0n2 /dev/nvme0n3
# 检查磁盘情况
[root@localhost ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sr0 11:0 1 1.7G 0 rom
nvme0n1 259:0 0 20G 0 disk
├─nvme0n1p1 259:1 0 1G 0 part /boot
└─nvme0n1p2 259:2 0 19G 0 part
├─rl-root 253:0 0 17G 0 lvm /
└─rl-swap 253:1 0 2G 0 lvm [SWAP]
nvme0n2 259:3 0 5G 0 disk
nvme0n3 259:4 0 5G 0 disk
nvme0n4 259:5 0 5G 0 disk /mnt/test
nvme0n5 259:6 0 5G 0 disk
nvme0n6 259:7 0 5G 0 disk
```
## RAID 1阵列实验
### 部署
按照上面实验中的方式,创建RAID1阵列以及完成挂载
```bash
[root@localhost ~]# mdadm -Cv /dev/md0 -a yes -n 2 -l 1 /dev/nvme0n2 /dev/nvme0n3
mdadm: Note: this array has metadata at the start and
may not be suitable as a boot device. If you plan to
store '/boot' on this device please ensure that
your boot-loader understands md/v1.x metadata, or use
--metadata=0.90
mdadm: size set to 5237760K
Continue creating array? y
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
[root@localhost ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sr0 11:0 1 1.7G 0 rom
nvme0n1 259:0 0 20G 0 disk
├─nvme0n1p1 259:1 0 1G 0 part /boot
└─nvme0n1p2 259:2 0 19G 0 part
├─rl-root 253:0 0 17G 0 lvm /
└─rl-swap 253:1 0 2G 0 lvm [SWAP]
nvme0n2 259:3 0 5G 0 disk
└─md0 9:0 0 5G 0 raid1
nvme0n3 259:4 0 5G 0 disk
└─md0 9:0 0 5G 0 raid1
nvme0n4 259:5 0 5G 0 disk /mnt/test
nvme0n5 259:6 0 5G 0 disk
nvme0n6 259:7 0 5G 0 disk
[root@localhost ~]# mkfs.ext4 /dev/md0
mke2fs 1.46.5 (30-Dec-2021)
/dev/md0 contains a ext4 file system
last mounted on /mnt/RAID0 on Thu Nov 14 16:39:48 2024
Proceed anyway? (y,N) y
Creating filesystem with 1309440 4k blocks and 327680 inodes
Filesystem UUID: fa3601df-6ddb-4471-afcc-fbf501a8e891
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
[root@localhost ~]# mkdir /mnt/RAID1
[root@localhost ~]# mount /dev/md0 /mnt/RAID1
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 872M 0 872M 0% /dev/shm
tmpfs 349M 6.3M 343M 2% /run
/dev/mapper/rl-root 17G 1.7G 16G 10% /
/dev/nvme0n1p1 960M 261M 700M 28% /boot
tmpfs 175M 0 175M 0% /run/user/0
/dev/nvme0n4 4.9G 1.1G 3.6G 22% /mnt/test
/dev/md0 4.9G 24K 4.6G 1% /mnt/RAID1
```
**注意最后的磁盘大小,我们将使用两块大小为5G的磁盘创建RAID1阵列。但是发现最后的磁盘大小还是5G,这也验证了RAID 1的特性,两块磁盘存放一样的数据,将数据镜像化,所以可用空间也会打对折**
### 磁盘写入测试
```sh
[root@localhost ~]# fio --name=write_test --filename=/mnt/RAID1/testfile --size=1G --bs=1M --rw=write --direct=1 --numjobs=1
write_test: (g=0): rw=write, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1
fio-3.35
Starting 1 process
write_test: Laying out IO file (1 file / 1024MiB)
Jobs: 1 (f=1)
write_test: (groupid=0, jobs=1): err= 0: pid=29656: Thu Nov 14 16:48:10 2024
write: IOPS=726, BW=727MiB/s (762MB/s)(1024MiB/1409msec); 0 zone resets
clat (usec): min=1057, max=6693, avg=1349.52, stdev=401.77
lat (usec): min=1074, max=6748, avg=1372.68, stdev=404.55
clat percentiles (usec):
| 1.00th=[ 1090], 5.00th=[ 1156], 10.00th=[ 1172], 20.00th=[ 1205],
| 30.00th=[ 1221], 40.00th=[ 1237], 50.00th=[ 1270], 60.00th=[ 1303],
| 70.00th=[ 1336], 80.00th=[ 1385], 90.00th=[ 1500], 95.00th=[ 1713],
| 99.00th=[ 3097], 99.50th=[ 3884], 99.90th=[ 5866], 99.95th=[ 6718],
| 99.99th=[ 6718]
bw ( KiB/s): min=716800, max=763904, per=99.48%, avg=740352.00, stdev=33307.56, samples=2
iops : min= 700, max= 746, avg=723.00, stdev=32.53, samples=2
lat (msec) : 2=96.58%, 4=2.93%, 10=0.49%
cpu : usr=0.36%, sys=7.53%, ctx=1031, majf=0, minf=9
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,1024,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
WRITE: bw=727MiB/s (762MB/s), 727MiB/s-727MiB/s (762MB/s-762MB/s), io=1024MiB (1074MB), run=1409-1409msec
Disk stats (read/write):
md0: ios=0/2009, merge=0/0, ticks=0/2531, in_queue=2531, util=92.94%, aggrios=0/2050, aggrmerge=0/0, aggrticks=0/2499, aggrin_queue=2500, aggrutil=91.91%
nvme0n2: ios=0/2050, merge=0/0, ticks=0/2476, in_queue=2477, util=91.91%
nvme0n3: ios=0/2050, merge=0/0, ticks=0/2522, in_queue=2523, util=91.91%
```
从测试结果中可以看见,RAID 1阵列的磁盘写入速度会比单块磁盘相对慢一点,因为RAID 1阵列是将一份数据写入两遍。
## RAID 10阵列实验
建议恢复快照到磁盘刚添加磁盘的状态。最少需要4块额外的硬盘
### 部署
1. 创建RAID 10阵列
```sh
[root@localhost ~]# mdadm -Cv /dev/md0 -a yes -n 4 -l 10 /dev/nvme0n2 /dev/nvme0n3 /dev/nvme0n4 /dev/nvme0n5
mdadm: layout defaults to n2
mdadm: layout defaults to n2
mdadm: chunk size defaults to 512K
mdadm: size set to 5237760K
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
[root@localhost ~]# mkfs.ext4 /dev/md0
mke2fs 1.46.5 (30-Dec-2021)
Creating filesystem with 2618880 4k blocks and 655360 inodes
Filesystem UUID: bd12aabd-52c7-41c3-81b8-bfb89a8ee580
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
[root@localhost ~]# mkdir /mnt/RAID10
[root@localhost ~]# mount /dev/md0 /mnt/RAID10
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 872M 0 872M 0% /dev/shm
tmpfs 349M 6.3M 343M 2% /run
/dev/mapper/rl-root 17G 1.7G 16G 10% /
/dev/nvme0n1p1 960M 261M 700M 28% /boot
tmpfs 175M 0 175M 0% /run/user/0
/dev/md0 9.8G 24K 9.3G 1% /mnt/RAID10
# 这里可以看到,虽然我们使用了4块大小为5G的硬盘,但是最后的实际大小只有10G。
```
2. 检查整列情况
```sh
[root@localhost ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Nov 14 17:07:34 2024
Raid Level : raid10
Array Size : 10475520 (9.99 GiB 10.73 GB)
Used Dev Size : 5237760 (5.00 GiB 5.36 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Nov 14 17:21:26 2024
State : clean
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 7011a5e6:862c3556:6bbba92b:8a61ce4e
Events : 17
Number Major Minor RaidDevice State
0 259 3 0 active sync set-A /dev/nvme0n2
1 259 4 1 active sync set-B /dev/nvme0n3
2 259 5 2 active sync set-A /dev/nvme0n4
3 259 6 3 active sync set-B /dev/nvme0n5
```
### 磁盘写入测试
```sh
[root@localhost RAID10]# fio --name=write_test --filename=/mnt/RAID10/testfile --size=1G --bs=1M --rw=write --direct=1 --numjobs=1
write_test: (g=0): rw=write, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1
fio-3.35
Starting 1 process
write_test: Laying out IO file (1 file / 1024MiB)
Jobs: 1 (f=1)
write_test: (groupid=0, jobs=1): err= 0: pid=27150: Thu Nov 14 17:29:34 2024
write: IOPS=715, BW=715MiB/s (750MB/s)(1024MiB/1432msec); 0 zone resets
clat (usec): min=1122, max=5646, avg=1373.87, stdev=264.26
lat (usec): min=1140, max=5741, avg=1395.28, stdev=266.74
clat percentiles (usec):
| 1.00th=[ 1156], 5.00th=[ 1205], 10.00th=[ 1221], 20.00th=[ 1254],
| 30.00th=[ 1287], 40.00th=[ 1303], 50.00th=[ 1336], 60.00th=[ 1369],
| 70.00th=[ 1401], 80.00th=[ 1450], 90.00th=[ 1516], 95.00th=[ 1614],
| 99.00th=[ 2040], 99.50th=[ 2606], 99.90th=[ 5669], 99.95th=[ 5669],
| 99.99th=[ 5669]
bw ( KiB/s): min=733184, max=737852, per=100.00%, avg=735518.00, stdev=3300.77, samples=2
iops : min= 716, max= 720, avg=718.00, stdev= 2.83, samples=2
lat (msec) : 2=98.73%, 4=1.07%, 10=0.20%
cpu : usr=0.49%, sys=6.57%, ctx=1026, majf=0, minf=10
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,1024,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
WRITE: bw=715MiB/s (750MB/s), 715MiB/s-715MiB/s (750MB/s-750MB/s), io=1024MiB (1074MB), run=1432-1432msec
Disk stats (read/write):
md0: ios=0/1984, merge=0/0, ticks=0/2554, in_queue=2554, util=93.47%, aggrios=0/1024, aggrmerge=0/0, aggrticks=0/1284, aggrin_queue=1284, aggrutil=92.57%
nvme0n4: ios=0/1024, merge=0/0, ticks=0/1272, in_queue=1272, util=92.31%
nvme0n2: ios=0/1024, merge=0/0, ticks=0/1277, in_queue=1278, util=92.31%
nvme0n5: ios=0/1024, merge=0/0, ticks=0/1312, in_queue=1312, util=92.57%
nvme0n3: ios=0/1024, merge=0/0, ticks=0/1277, in_queue=1277, util=92.31%
```
### 损坏磁盘阵列及修复
在确认有一块物理硬盘设备出现损坏而不能继续正常使用后,应该使用mdadm命令将其移除,然后查看RAID磁盘阵列的状态,可以发现状态已经改变。
```bash
[root@localhost RAID10]# mdadm /dev/md0 -f /dev/nvme0n2
mdadm: set /dev/nvme0n2 faulty in /dev/md0
[root@localhost RAID10]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Nov 14 17:07:34 2024
Raid Level : raid10
Array Size : 10475520 (9.99 GiB 10.73 GB)
Used Dev Size : 5237760 (5.00 GiB 5.36 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Fri Nov 15 10:05:55 2024
State : clean, degraded
Active Devices : 3
Working Devices : 3
Failed Devices : 1
Spare Devices : 0
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 7011a5e6:862c3556:6bbba92b:8a61ce4e
Events : 19
Number Major Minor RaidDevice State
- 0 0 0 removed
1 259 4 1 active sync set-B /dev/nvme0n3
2 259 5 2 active sync set-A /dev/nvme0n4
3 259 6 3 active sync set-B /dev/nvme0n5
0 259 3 - faulty /dev/nvme0n2
```
在RAID 10级别的磁盘阵列中,当RAID 1磁盘阵列中存在一个故障盘时并不影响RAID 10磁盘阵列的使用。当购买了新的硬盘设备后再使用mdadm命令来予以替换即可,在此期间我们可以在/RAID目录中正常地创建或删除文件。由于我们是在虚拟机中模拟硬盘,所以先重启系统,然后再把新的硬盘添加到RAID磁盘阵列中。
```bash
[root@localhost ~]# umount /mnt/RAID10
#有时候失败,告诉设备忙,-f参数都没用
#可以使用fuser -mk /mnt/RAID10命令杀死所有占用该文件的进程
# 先热移除/dev/nvme0n2
[root@localhost ~]# mdadm /dev/md0 -r /dev/nvme0n2
mdadm: hot removed /dev/nvme0n2 from /dev/md0
[root@localhost ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Nov 14 17:07:34 2024
Raid Level : raid10
Array Size : 10475520 (9.99 GiB 10.73 GB)
Used Dev Size : 5237760 (5.00 GiB 5.36 GB)
Raid Devices : 4
Total Devices : 3
Persistence : Superblock is persistent
Update Time : Fri Nov 15 10:09:16 2024
State : clean, degraded
Active Devices : 3
Working Devices : 3
Failed Devices : 0
Spare Devices : 0
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 7011a5e6:862c3556:6bbba92b:8a61ce4e
Events : 22
Number Major Minor RaidDevice State
- 0 0 0 removed
1 259 4 1 active sync set-B /dev/nvme0n3
2 259 5 2 active sync set-A /dev/nvme0n4
3 259 6 3 active sync set-B /dev/nvme0n5
# 再重新添加/dev/nvme0n2
[root@localhost ~]# mdadm /dev/md0 -a /dev/nvme0n2
mdadm: added /dev/nvme0n2
[root@localhost ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Thu Nov 14 17:07:34 2024
Raid Level : raid10
Array Size : 10475520 (9.99 GiB 10.73 GB)
Used Dev Size : 5237760 (5.00 GiB 5.36 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Fri Nov 15 10:10:25 2024
State : clean, degraded, recovering
Active Devices : 3
Working Devices : 4
Failed Devices : 0
Spare Devices : 1
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Rebuild Status : 31% complete
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 7011a5e6:862c3556:6bbba92b:8a61ce4e
Events : 28
Number Major Minor RaidDevice State
4 259 3 0 spare rebuilding /dev/nvme0n2
1 259 4 1 active sync set-B /dev/nvme0n3
2 259 5 2 active sync set-A /dev/nvme0n4
3 259 6 3 active sync set-B /dev/nvme0n5
# 会发现,刚添加上的磁盘处于rebuilding的状态,等待一会儿,就会恢复正常了。
# 重新再次挂载即可正常使用
[root@localhost ~]# mount /dev/md0 /mnt/RAID10/
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 872M 0 872M 0% /dev/shm
tmpfs 349M 6.3M 343M 2% /run
/dev/mapper/rl-root 17G 1.7G 16G 10% /
/dev/nvme0n1p1 960M 261M 700M 28% /boot
tmpfs 175M 0 175M 0% /run/user/0
/dev/md0 9.8G 1.1G 8.3G 11% /mnt/RAID10
# 有的时候,可能会存在/dev/nvme0n2无法添加的情况,对于这种情况,只能将整个整列全部删除干净之后重新创建
```
## RAID 5阵列实验+备份盘
为了避免多个实验之间相互发生冲突,我们需要保证每个实验的相对独立性,为此需要大家自行将虚拟机还原到初始状态。
部署RAID 5磁盘阵列时,至少需要用到3块硬盘,还需要再加一块备份硬盘,所以总计需要在虚拟机中模拟4块硬盘设备
现在创建一个RAID 5磁盘阵列+备份盘。在下面的命令中,参数-n 3代表创建这个RAID 5磁盘阵列所需的硬盘数,参数-l 5代表RAID的级别,而参数-x 1则代表有一块备份盘。当查看/dev/md0(即RAID 5磁盘阵列的名称)磁盘阵列的时候就能看到有一块备份盘在等待中了。
```bash
[root@localhost ~]# mdadm -Cv /dev/md0 -n 3 -l 5 -x 1 /dev/nvme0n2 /dev/nvme0n3 /dev/nvme0n4 /dev/nvme0n5
mdadm: layout defaults to left-symmetric
mdadm: layout defaults to left-symmetric
mdadm: chunk size defaults to 512K
mdadm: size set to 5237760K
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
[root@localhost ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Fri Nov 15 10:33:07 2024
Raid Level : raid5
Array Size : 10475520 (9.99 GiB 10.73 GB)
Used Dev Size : 5237760 (5.00 GiB 5.36 GB)
Raid Devices : 3
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Fri Nov 15 10:33:33 2024
State : clean
Active Devices : 3
Working Devices : 4
Failed Devices : 0
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Consistency Policy : resync
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 8f9130a4:06668353:958e7628:985d1167
Events : 18
Number Major Minor RaidDevice State
0 259 3 0 active sync /dev/nvme0n2
1 259 4 1 active sync /dev/nvme0n3
4 259 5 2 active sync /dev/nvme0n4
3 259 6 - spare /dev/nvme0n5
```
将部署好的RAID 5磁盘阵列格式化为ext4文件格式,然后挂载到目录上,之后就可以使用了。
```bash
[root@localhost ~]# mkfs.ext4 /dev/md0
mke2fs 1.46.5 (30-Dec-2021)
Creating filesystem with 2618880 4k blocks and 655360 inodes
Filesystem UUID: 33c5ee4e-82de-4c0f-98f1-88cda85292ea
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632
Allocating group tables: done
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
[root@localhost ~]# mkdir /mnt/RAID5
[root@localhost ~]# echo "/dev/md0 /mnt/RAID5 ext4 defaults 0 0" >> /etc/fstab
[root@localhost ~]# mount -a
mount: (hint) your fstab has been modified, but systemd still uses
the old version; use 'systemctl daemon-reload' to reload.
[root@localhost ~]# systemctl daemon-reload
[root@localhost ~]# mount -a
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 4.0M 0 4.0M 0% /dev
tmpfs 872M 0 872M 0% /dev/shm
tmpfs 349M 6.3M 343M 2% /run
/dev/mapper/rl-root 17G 1.7G 16G 10% /
/dev/nvme0n1p1 960M 261M 700M 28% /boot
tmpfs 175M 0 175M 0% /run/user/0
/dev/md0 9.8G 24K 9.3G 1% /mnt/RAID5
```
把硬盘设备/dev/nvme0n2移出磁盘阵列,然后迅速查看/dev/md0磁盘阵列的状态
```bash
[root@localhost ~]# mdadm /dev/md0 -f /dev/nvme0n2
mdadm: set /dev/nvme0n2 faulty in /dev/md0
# /dev/nvme0n5由原来的spare顶上来变成spare-building
[root@localhost ~]# mdadm -D /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Fri Nov 15 10:33:07 2024
Raid Level : raid5
Array Size : 10475520 (9.99 GiB 10.73 GB)
Used Dev Size : 5237760 (5.00 GiB 5.36 GB)
Raid Devices : 3
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Fri Nov 15 10:41:21 2024
State : clean, degraded, recovering
Active Devices : 2
Working Devices : 3
Failed Devices : 1
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Consistency Policy : resync
Rebuild Status : 11% complete
Name : localhost.localdomain:0 (local to host localhost.localdomain)
UUID : 8f9130a4:06668353:958e7628:985d1167
Events : 21
Number Major Minor RaidDevice State
3 259 6 0 spare rebuilding /dev/nvme0n5
1 259 4 1 active sync /dev/nvme0n3
4 259 5 2 active sync /dev/nvme0n4
0 259 3 - faulty /dev/nvme0n2
# 然后过一会儿,/dev/nvme0n5的状态就会变成active sync
```